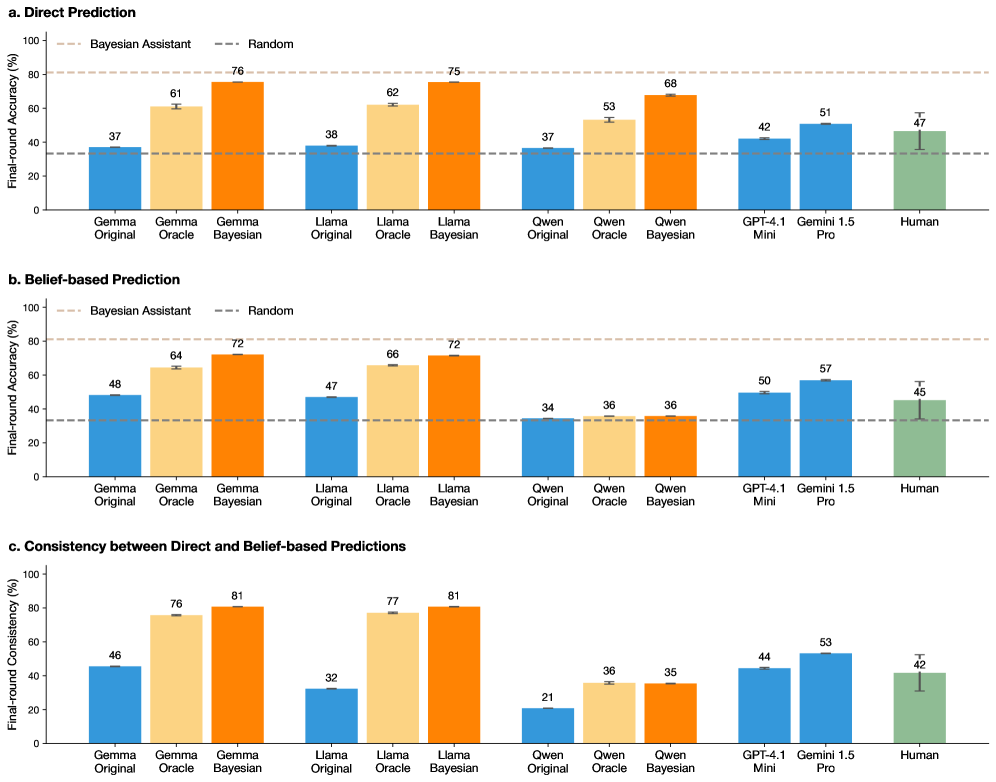
## Bar Charts: Model Performance Comparison Across Prediction Tasks
### Overview
The image contains three horizontal bar charts (labeled a, b, and c) comparing the performance of various AI models and humans on two prediction tasks and their consistency. The charts are titled "Direct Prediction," "Belief-based Prediction," and "Consistency between Direct and Belief-based Predictions." Each chart compares multiple model families (Gemma, Llama, Qwen) in three variants (Original, Oracle, Bayesian), alongside GPT-4.1 Mini, Gemini 1.5 Pro, and Human performance.
### Components/Axes
* **Chart Titles:**
* a. Direct Prediction
* b. Belief-based Prediction
* c. Consistency between Direct and Belief-based Predictions
* **Y-Axis Labels:**
* Charts a & b: "Final-round Accuracy (%)"
* Chart c: "Final-round Consistency (%)"
* **Y-Axis Scale:** 0 to 100 for all charts, with major ticks every 20 units.
* **X-Axis Categories (Identical for all charts):**
* Gemma Original, Gemma Oracle, Gemma Bayesian
* Llama Original, Llama Oracle, Llama Bayesian
* Qwen Original, Qwen Oracle, Qwen Bayesian
* GPT-4.1 Mini, Gemini 1.5 Pro, Human
* **Legend (Present in all charts, positioned top-left):**
* `--- Bayesian Assistant` (Dashed light brown line)
* `--- Random` (Dashed grey line)
* **Bar Colors:**
* Original variants: Blue
* Oracle variants: Light orange/peach
* Bayesian variants: Dark orange
* GPT-4.1 Mini & Gemini 1.5 Pro: Blue (same shade as "Original")
* Human: Green
* **Error Bars:** Present on all bars, indicating variability or confidence intervals.
### Detailed Analysis
#### **Chart a. Direct Prediction**
* **Trend:** For each model family (Gemma, Llama, Qwen), performance increases from Original -> Oracle -> Bayesian. The Bayesian variant consistently achieves the highest accuracy within its family.
* **Data Points (Approximate % Accuracy):**
* **Gemma:** Original ~37, Oracle ~61, Bayesian ~76
* **Llama:** Original ~38, Oracle ~62, Bayesian ~75
* **Qwen:** Original ~37, Oracle ~53, Bayesian ~68
* **Other Models:** GPT-4.1 Mini ~42, Gemini 1.5 Pro ~51, Human ~47
* **Benchmarks:** The "Bayesian Assistant" dashed line is at ~80%. The "Random" dashed line is at ~33%.
#### **Chart b. Belief-based Prediction**
* **Trend:** Similar upward trend from Original to Bayesian for Gemma and Llama. For Qwen, performance is flat across all three variants (~34-36). GPT-4.1 Mini and Gemini 1.5 Pro show moderate performance.
* **Data Points (Approximate % Accuracy):**
* **Gemma:** Original ~48, Oracle ~64, Bayesian ~72
* **Llama:** Original ~47, Oracle ~66, Bayesian ~72
* **Qwen:** Original ~34, Oracle ~36, Bayesian ~36
* **Other Models:** GPT-4.1 Mini ~50, Gemini 1.5 Pro ~57, Human ~45
* **Benchmarks:** "Bayesian Assistant" line at ~80%, "Random" line at ~33%.
#### **Chart c. Consistency between Direct and Belief-based Predictions**
* **Trend:** Consistency generally increases from Original to Oracle to Bayesian for Gemma and Llama. Qwen shows low consistency, with a slight increase from Original to Oracle/Bayesian. Gemini 1.5 Pro shows the highest consistency among non-family models.
* **Data Points (Approximate % Consistency):**
* **Gemma:** Original ~46, Oracle ~76, Bayesian ~81
* **Llama:** Original ~32, Oracle ~77, Bayesian ~81
* **Qwen:** Original ~21, Oracle ~36, Bayesian ~35
* **Other Models:** GPT-4.1 Mini ~44, Gemini 1.5 Pro ~53, Human ~42
### Key Observations
1. **Bayesian Superiority:** The "Bayesian" variant of each model family (Gemma, Llama) is the top performer in both accuracy tasks (Charts a & b) and shows the highest internal consistency (Chart c).
2. **Qwen Anomaly:** The Qwen model family shows a distinct pattern. While its Bayesian variant improves on Direct Prediction (Chart a), it shows no improvement in Belief-based Prediction (Chart b) and has significantly lower consistency scores (Chart c) compared to Gemma and Llama.
3. **Human vs. Model:** Human performance (~47% Direct, ~45% Belief-based) is generally outperformed by the Oracle and Bayesian variants of Gemma and Llama, and by Gemini 1.5 Pro in the Belief-based task.
4. **Benchmark Context:** The "Bayesian Assistant" benchmark (~80%) is only approached or matched by the top-performing Bayesian model variants (Gemma/Llama Bayesian in Direct Prediction, Gemma/Llama Bayesian in Consistency). All models and humans perform well above the "Random" baseline (~33%).
5. **Gemini 1.5 Pro Strength:** Among the standalone models, Gemini 1.5 Pro consistently outperforms GPT-4.1 Mini and shows the highest consistency score outside the Bayesian model families.
### Interpretation
This data strongly suggests that integrating Bayesian methods ("Bayesian" variants) into language models significantly enhances both their predictive accuracy and the consistency between their direct outputs and their stated beliefs. The near-identical high performance of Gemma-Bayesian and Llama-Bayesian indicates this improvement may be a robust effect of the method rather than a specific model architecture.
The Qwen family's failure to improve in the Belief-based task and its low consistency scores point to a potential disconnect in how that model processes or represents belief states compared to direct prediction. This could indicate a difference in training, architecture, or internal representation.
The fact that advanced proprietary models (GPT-4.1 Mini, Gemini 1.5 Pro) are outperformed by open-weight models equipped with Bayesian techniques (Gemma/Llama Oracle/Bayesian) highlights the potential of specialized inference methods to boost performance beyond raw model scale. The "Bayesian Assistant" line likely represents a theoretical or ideal performance ceiling for this methodology, which the best models are nearing.
Overall, the charts make a case for the value of Bayesian approaches in making model predictions more accurate, reliable (consistent), and aligned with their internal belief states—a crucial factor for trustworthy AI.