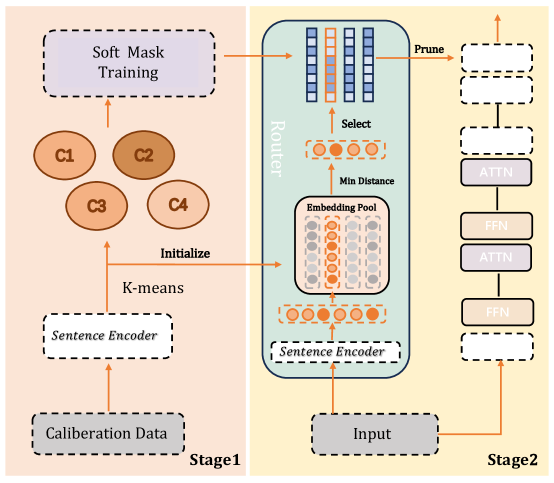
## Diagram: Two-Stage Machine Learning System Architecture
### Overview
The diagram illustrates a two-stage machine learning system architecture, likely for natural language processing (NLP) or similar tasks. It combines clustering, attention mechanisms, and feed-forward networks (FFN) with iterative refinement. Stage 1 focuses on calibration and clustering, while Stage 2 emphasizes dynamic routing and model refinement.
### Components/Axes
#### Stage 1 (Left Side):
1. **Soft Mask Training**: A process involving probabilistic masking, likely for model calibration.
2. **Calibration Data**: Input data used to train the system.
3. **Sentence Encoder**: Encodes input data into embeddings.
4. **K-means**: A clustering algorithm initialized with embeddings from the Sentence Encoder.
5. **Initialization**: Arrows indicate flow from Calibration Data → Sentence Encoder → K-means.
#### Stage 2 (Right Side):
1. **Input**: Raw data fed into the system.
2. **Sentence Encoder**: Reused from Stage 1 to encode input.
3. **Router**: Directs embeddings to an **Embedding Pool** based on **Min Distance** (likely nearest neighbor search).
4. **Select**: Chooses embeddings from the pool.
5. **Prune**: Removes irrelevant or redundant data.
6. **ATTN (Attention)**: Processes selected embeddings.
7. **FFN (Feed-Forward Network)**: Applies non-linear transformations.
8. **Loop**: Outputs from FFN loop back into the system for iterative refinement.
### Detailed Analysis
- **Stage 1 Flow**:
- Calibration Data → Sentence Encoder → K-means → Soft Mask Training.
- K-means initializes clusters (C1–C4) for soft masking.
- **Stage 2 Flow**:
- Input → Sentence Encoder → Router → Embedding Pool → Select → Prune → ATTN → FFN → Loop.
- The **Router** uses **Min Distance** to map embeddings to the closest cluster (C1–C4).
- **ATTN** and **FFN** form a recurrent loop, suggesting iterative refinement of embeddings.
### Key Observations
1. **Redundancy**: The Sentence Encoder is reused in both stages, indicating shared representation learning.
2. **Dynamic Routing**: The Router’s use of Min Distance implies a nearest-neighbor approach for embedding selection.
3. **Iterative Refinement**: The ATTN-FFN loop suggests a transformer-like architecture with feedback for optimization.
4. **Pruning**: Likely removes low-confidence or irrelevant embeddings to improve efficiency.
### Interpretation
This architecture combines **clustering-based calibration** (Stage 1) with **attention-driven refinement** (Stage 2). The reuse of the Sentence Encoder ensures consistent feature extraction, while the Router’s Min Distance mechanism enables efficient embedding selection. The ATTN-FFN loop mirrors transformer architectures, where attention mechanisms and feed-forward layers iteratively refine representations.
The system likely balances **efficiency** (via pruning and clustering) with **accuracy** (via attention and iterative refinement). The absence of explicit numerical values suggests this is a conceptual diagram, emphasizing component relationships over quantitative performance metrics.
**Note**: No numerical data or trends are present in the diagram. All components are labeled, and flow directions are explicitly defined via arrows.