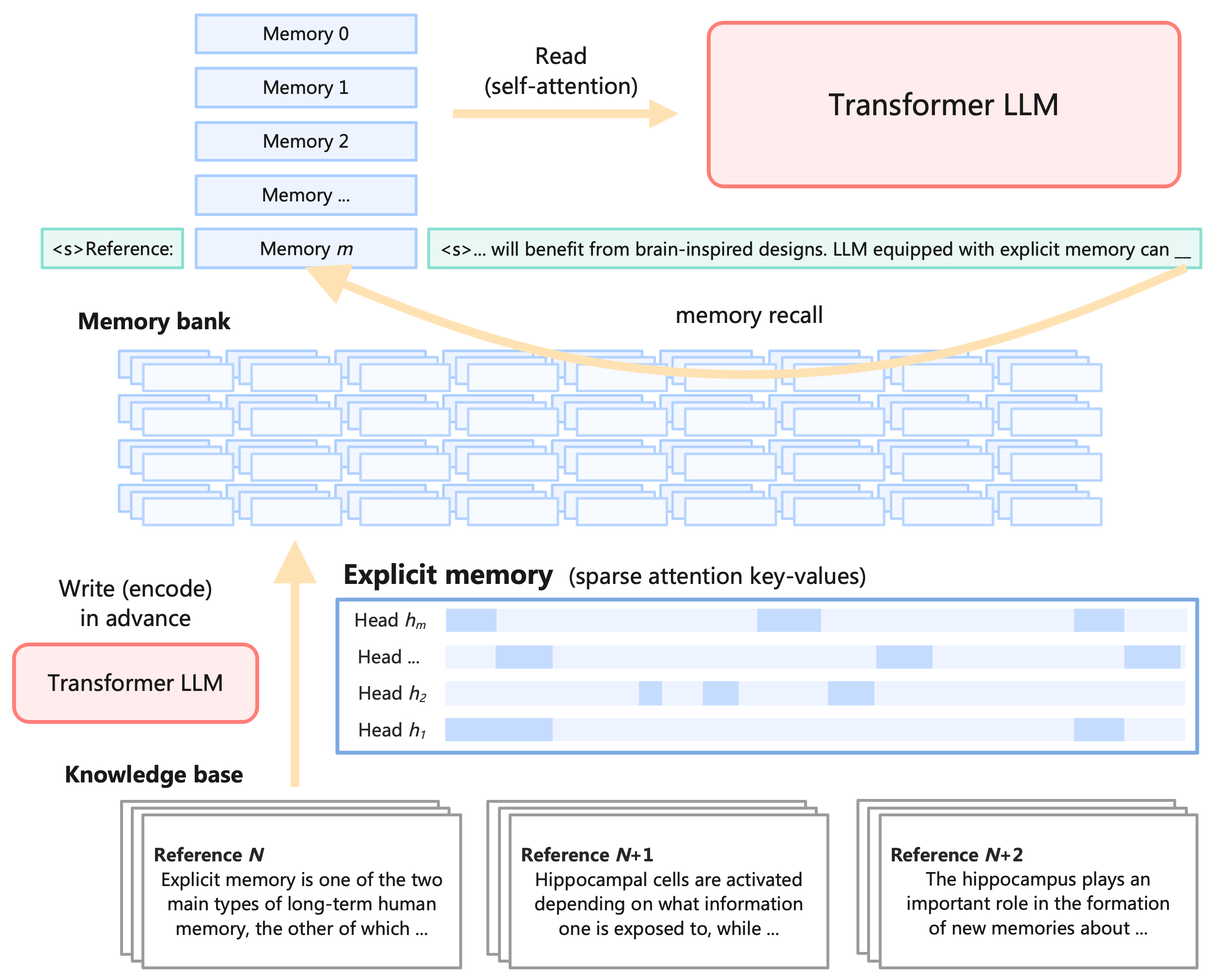
## Diagram: Transformer LLM with Explicit Memory Architecture
### Overview
This image is a technical system architecture diagram illustrating a proposed design for a Large Language Model (LLM) that incorporates an explicit, brain-inspired memory system. The diagram shows the flow of information between a core Transformer LLM, a memory bank, an explicit memory module, and an external knowledge base. The central concept is augmenting a standard Transformer with mechanisms to "write" (encode) and "read" (recall) information from a structured memory store, mimicking aspects of human long-term memory.
### Components/Axes
The diagram is composed of several interconnected components, labeled as follows:
1. **Transformer LLM (Top Right):** A large, red-outlined box representing the core language model.
2. **Memory Bank (Top Left):** A vertical stack of light blue rectangles labeled `Memory 0`, `Memory 1`, `Memory 2`, `Memory ...`, and `Memory m`.
3. **Explicit Memory (Center):** A blue-outlined box labeled `Explicit memory (sparse attention key-values)`. Inside, it contains horizontal bars representing attention heads: `Head h₁`, `Head h₂`, `Head ...`, and `Head hₘ`. Each bar has a pattern of light blue blocks, indicating sparse activation.
4. **Knowledge Base (Bottom):** Three overlapping card-like elements labeled:
* `Reference N`
* `Reference N+1`
* `Reference N+2`
5. **Text Snippets:**
* A green box on the left: `<s>Reference:`
* A green box on the right: `<s>... will benefit from brain-inspired designs. LLM equipped with explicit memory can __`
* Text within the Knowledge Base cards (see Detailed Analysis).
### Detailed Analysis
**Data Flow and Processes:**
The diagram defines three primary data flows, indicated by large, light orange arrows:
1. **Read (self-attention):** An arrow points from the `Memory bank` to the `Transformer LLM`. This indicates the LLM can access and attend to the stored memories during its operation.
2. **Write (encode) in advance:** An arrow points from a second `Transformer LLM` box (bottom left) up to the `Explicit memory` module. This suggests a pre-processing or training phase where the model encodes information into the sparse key-value format.
3. **Memory recall:** A curved arrow originates from the right-hand text snippet (`<s>... will benefit from brain-inspired designs...`) and points to a specific memory slot (`Memory m`) in the bank. This illustrates the process of retrieving a relevant memory based on a context or query.
**Content of Knowledge Base References:**
The text on the reference cards is partially visible:
* **Reference N:** "Explicit memory is one of the two main types of long-term human memory, the other of which ..."
* **Reference N+1:** "Hippocampal cells are activated depending on what information one is exposed to, while ..."
* **Reference N+2:** "The hippocampus plays an important role in the formation of new memories about ..."
**Spatial Grounding:**
* The `Memory bank` is positioned in the top-left quadrant.
* The primary `Transformer LLM` is in the top-right quadrant.
* The `Explicit memory` module is centrally located, acting as a bridge.
* The `Knowledge base` occupies the bottom third of the diagram.
* The `Write` process originates from the lower-left, while the `Read` process is at the top.
### Key Observations
1. **Dual-Phase Operation:** The architecture separates the "write/encode" phase (bottom) from the "read/recall" phase (top), suggesting memory is populated before or during a separate training/inference step.
2. **Sparse Memory Representation:** The `Explicit memory` is visualized as sparse patterns across multiple attention heads (`h₁` to `hₘ`), implying an efficient, distributed storage mechanism rather than a dense buffer.
3. **Brain-Inspired Analogy:** The text in the knowledge base references (`Reference N`, `N+1`, `N+2`) explicitly link the design to neuroscience concepts like human long-term memory, hippocampal function, and memory formation, providing the conceptual motivation for the architecture.
4. **Context-Driven Recall:** The `memory recall` arrow shows retrieval is triggered by a specific input sequence (the text snippet), indicating a content-addressable memory system.
### Interpretation
This diagram proposes a significant augmentation to the standard Transformer LLM paradigm. It addresses a key limitation—the model's static, parametric knowledge—by introducing a dynamic, external **explicit memory** system.
* **How it works:** The system functions in two stages. First, a **write/encode** process uses the LLM to transform information from a `Knowledge base` into a structured, sparse format stored in the `Explicit memory` module. This memory is then organized into a searchable `Memory bank`. During normal operation, the LLM can perform a **read** operation via self-attention to access this bank. Crucially, **memory recall** is context-sensitive; a given input prompt can trigger the retrieval of specific, relevant memories (like `Memory m`), which are then fed back into the LLM's context.
* **Why it matters:** This design aims to create an LLM that can continuously learn and access a vast, updatable repository of knowledge without retraining its core parameters. It mimics the human ability to form new long-term memories (hippocampal function) and recall them when relevant. The sparse attention key-value representation suggests a focus on computational efficiency. The overall goal is to move beyond the fixed "knowledge cutoff" of traditional LLMs toward a more flexible, lifelong learning system that can integrate new information and recall it with precision, much like a human expert consulting their memory and notes.