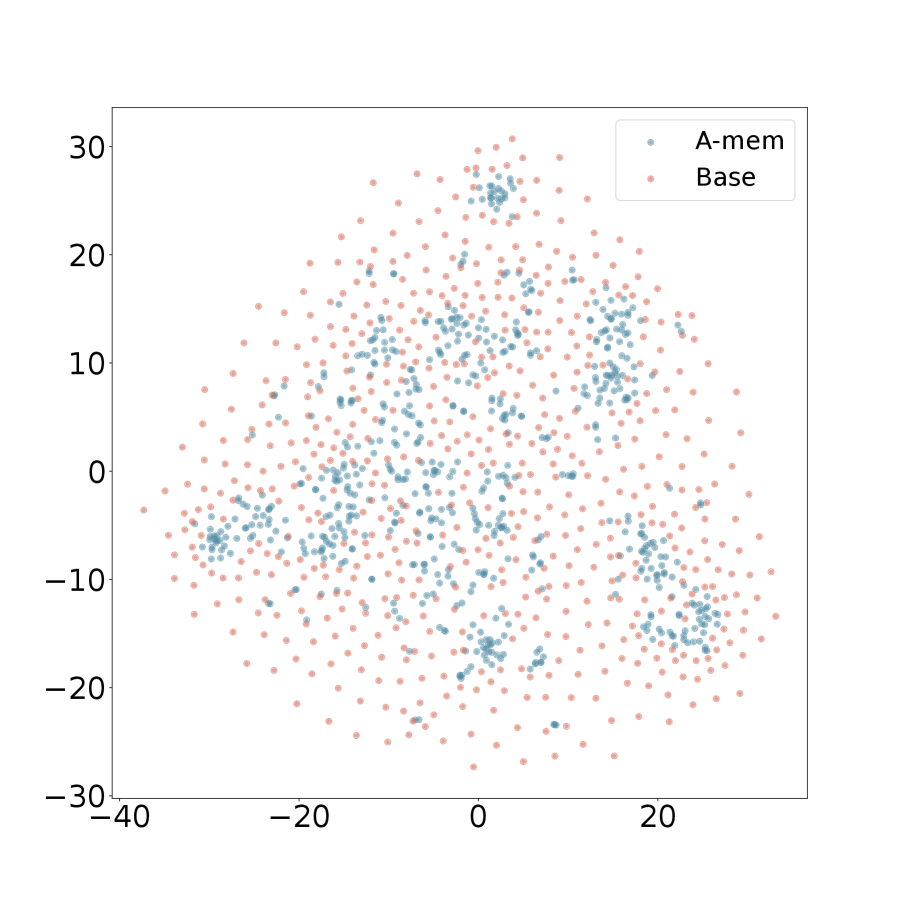
## Scatter Plot: A-mem vs Base
### Overview
The image is a scatter plot comparing two datasets, "A-mem" and "Base". The plot displays the distribution of data points for each dataset across a two-dimensional space. The x and y axes are not explicitly labeled, but the data points are clustered in distinct regions.
### Components/Axes
* **X-axis:** Ranges from approximately -40 to 30.
* **Y-axis:** Ranges from approximately -30 to 30.
* **Legend (Top-Right):**
* A-mem (Light Blue)
* Base (Light Red)
### Detailed Analysis
The scatter plot shows the distribution of two datasets, A-mem (light blue) and Base (light red). The data points are clustered, suggesting some underlying structure or grouping within the data.
* **A-mem (Light Blue):** The light blue data points are clustered in several distinct regions. These clusters appear to be more concentrated than the Base data points. The clusters are located approximately at:
* (-20, -5)
* (-5, -15)
* (0, 25)
* (5, 0)
* (15, -15)
* (20, 0)
* **Base (Light Red):** The light red data points are more dispersed compared to the A-mem data. They form a broader distribution, with a higher density around the clusters of A-mem.
### Key Observations
* The A-mem data exhibits clear clustering, indicating potential groupings or categories within that dataset.
* The Base data is more dispersed, suggesting a more uniform distribution or less distinct groupings.
* The clusters of A-mem appear to be surrounded by a higher density of Base data points.
### Interpretation
The scatter plot suggests that the "A-mem" dataset has a more structured organization compared to the "Base" dataset. The clustering of "A-mem" indicates that its data points may belong to distinct categories or groups. The "Base" dataset, on the other hand, appears to be more uniformly distributed, possibly representing a broader or less structured set of data. The higher density of "Base" data points around the "A-mem" clusters could indicate a relationship or interaction between the two datasets. The plot could be visualizing the results of a dimensionality reduction technique, where the original high-dimensional data is projected onto a two-dimensional space for visualization.