\n
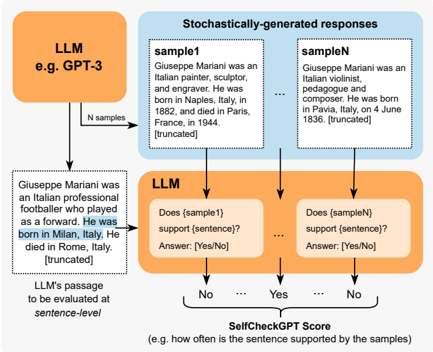
## Diagram: SelfCheckGPT Workflow
### Overview
This diagram illustrates the workflow of SelfCheckGPT, a system for evaluating the factual consistency of Large Language Model (LLM) outputs. It shows how an LLM generates multiple responses to a prompt, and how another instance of the LLM is used to assess whether those responses support a given passage.
### Components/Axes
The diagram consists of four main components:
1. **LLM (e.g. GPT-3):** Represented by an orange rectangle at the top-left.
2. **Stochastically-generated responses:** Represented by a blue rectangle at the top-right, containing multiple "sample" responses (sample1, sampleN, and "...")
3. **LLM (Evaluation):** Represented by an orange rectangle at the bottom-center, evaluating each sample against a sentence from the passage.
4. **SelfCheckGPT Score:** Represented by a green rectangle at the bottom, indicating the frequency of support from the samples.
Arrows indicate the flow of information between these components.
### Detailed Analysis or Content Details
* **LLM (e.g. GPT-3):** Generates "N samples".
* **Stochastically-generated responses:**
* **sample1:** "Giuseppe Mariani was an Italian painter, sculptor, and engraver. He was born in Naples, Italy, in 1882, and died in Paris, France, in 1944. [truncated]"
* **sampleN:** "Giuseppe Mariani was an Italian violinist, composer and composer. He was born in Pavia, Italy, on 4 June 1836. [truncated]"
* The "..." indicates that there are more samples not shown.
* **LLM (Evaluation):** Evaluates each sample against a sentence from the passage. The question posed is "Does (sampleX) support (sentence)?". The answer is either "Yes" or "No".
* **LLM's passage to be evaluated sentence-level:** "Giuseppe Mariani was an Italian professional footballer who played as a forward. He was born in Milan, Italy. He died in Rome, Italy. [truncated]"
* The sentence "He was born in Milan, Italy." is highlighted in blue.
* **SelfCheckGPT Score:** The score represents "e.g. how often is the sentence supported by the samples". The output is a series of "No" and "Yes" answers, indicating support or lack thereof from each sample.
### Key Observations
The diagram demonstrates a process of fact-checking LLM outputs by leveraging the LLM itself. The system generates multiple responses and then uses another instance of the LLM to determine if those responses align with a given passage. The SelfCheckGPT score provides a measure of confidence in the factual consistency of the LLM's output. The samples provided show conflicting information regarding Giuseppe Mariani's profession and birthplace, highlighting the potential for LLMs to generate inaccurate or inconsistent information.
### Interpretation
This diagram illustrates a method for evaluating the reliability of LLM-generated text. The core idea is to use the LLM's own capabilities to assess its outputs, creating a self-checking mechanism. The "SelfCheckGPT Score" is a crucial metric, indicating the degree to which the generated responses corroborate the information in the passage being evaluated. The conflicting information in the samples (painter vs. footballer, Naples vs. Milan) underscores the need for such evaluation methods, as LLMs can produce plausible but factually incorrect statements. The truncation of the samples suggests that the full context might be important for accurate evaluation. The diagram suggests a probabilistic approach to fact-checking, where the score reflects the frequency of support rather than a definitive "true" or "false" determination. This is a valuable approach given the inherent uncertainty in LLM outputs.