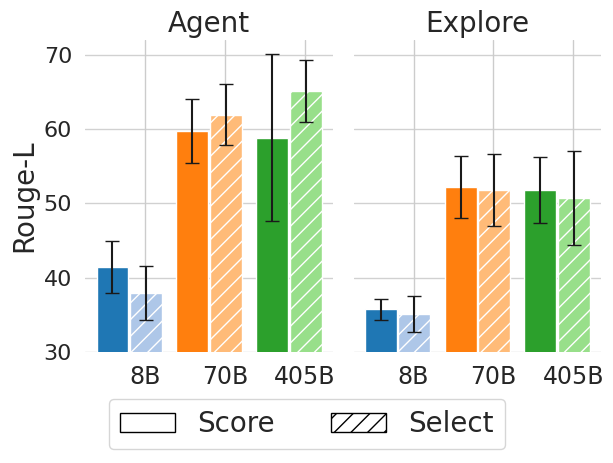
## Bar Chart: Agent and Explore Performance by Model Size
### Overview
The image is a grouped bar chart comparing the performance of three model sizes (8B, 70B, 405B) across two tasks ("Agent" and "Explore") using two metrics: "Score" (solid bars) and "Select" (striped bars). The y-axis measures "Rouge-L" (a text generation evaluation metric), and the x-axis categorizes data by model size and task.
### Components/Axes
- **X-axis**: Model sizes (8B, 70B, 405B) grouped under "Agent" and "Explore" tasks.
- **Y-axis**: Rouge-L scores (range: 30–70).
- **Legend**:
- Solid blue bars: "Score"
- Striped orange bars: "Select"
- **Error Bars**: Vertical lines with caps on top of each bar, indicating variability.
### Detailed Analysis
#### Agent Task
- **8B**:
- Score (blue): ~40 (error ±3)
- Select (orange): ~38 (error ±2)
- **70B**:
- Score (blue): ~60 (error ±4)
- Select (orange): ~62 (error ±3)
- **405B**:
- Score (blue): ~58 (error ±3)
- Select (orange): ~65 (error ±4)
#### Explore Task
- **8B**:
- Score (blue): ~35 (error ±2)
- Select (orange): ~33 (error ±1)
- **70B**:
- Score (blue): ~52 (error ±3)
- Select (orange): ~51 (error ±2)
- **405B**:
- Score (blue): ~51 (error ±2)
- Select (orange): ~50 (error ±3)
### Key Observations
1. **Model Size Impact**: Larger models (70B, 405B) consistently outperform smaller models (8B) in both tasks.
2. **Metric Comparison**:
- "Select" (orange) generally scores higher than "Score" (blue) across all model sizes and tasks.
- Exception: In the "Agent" task, the 8B model's "Score" (40) slightly exceeds its "Select" (38).
3. **Error Variability**: Larger models (405B) exhibit greater variability in "Select" scores (error ±4) compared to smaller models.
### Interpretation
The data suggests that model size is a critical factor in performance, with larger models achieving higher Rouge-L scores. The "Select" metric consistently outperforms "Score," except in the smallest model (8B) for the "Agent" task. The error bars indicate that while variability increases with model size, the trends remain robust. This implies that scaling model size improves performance, but the choice between "Score" and "Select" may depend on task-specific requirements or evaluation criteria.