\n
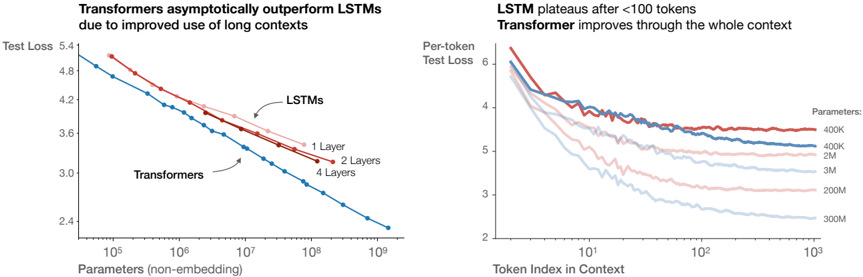
## Charts: Transformer vs LSTM Performance
### Overview
The image presents two charts comparing the performance of Transformer and LSTM models. The left chart shows Test Loss versus Parameters (non-embedding), demonstrating how Transformers asymptotically outperform LSTMs as the number of parameters increases. The right chart shows Per-token Test Loss versus Token Index in Context, illustrating that LSTMs plateau after approximately 100 tokens, while Transformers continue to improve with increasing context length.
### Components/Axes
**Left Chart:**
* **Title:** "Transformers asymptotically outperform LSTMs due to improved use of long contexts"
* **X-axis:** "Parameters (non-embedding)" - Logarithmic scale from approximately 10<sup>5</sup> to 10<sup>9</sup>.
* **Y-axis:** "Test Loss" - Scale from approximately 3.0 to 5.4.
* **Data Series:**
* "Transformers" (Blue line)
* "LSTMs" (Red lines)
* "1 Layer" (Dark Red)
* "2 Layers" (Light Red)
* "4 Layers" (Very Light Red)
**Right Chart:**
* **Title:** "LSTM plateaus after <100 tokens Transformer improves through the whole context"
* **X-axis:** "Token Index in Context" - Logarithmic scale from approximately 10<sup>0</sup> to 10<sup>3</sup>.
* **Y-axis:** "Per-token Test Loss" - Scale from approximately 2.0 to 6.0.
* **Legend:** "Parameters:"
* "400K" (Darkest Red)
* "2M" (Red)
* "3M" (Light Red)
* "200M" (Very Light Red)
* "300M" (Lightest Red)
### Detailed Analysis or Content Details
**Left Chart:**
* **Transformers (Blue Line):** The line slopes downward consistently, indicating a decrease in Test Loss as the number of parameters increases.
* At approximately 10<sup>5</sup> parameters, Test Loss is around 5.0.
* At approximately 10<sup>7</sup> parameters, Test Loss is around 3.8.
* At approximately 10<sup>9</sup> parameters, Test Loss is around 3.0.
* **LSTMs (Red Lines):** The lines initially decrease, but the rate of decrease slows down and eventually plateaus.
* **1 Layer (Dark Red):** Starts around 5.2, plateaus around 4.2.
* **2 Layers (Light Red):** Starts around 5.0, plateaus around 3.9.
* **4 Layers (Very Light Red):** Starts around 4.8, plateaus around 3.7.
**Right Chart:**
* **400K (Darkest Red):** Starts around 5.8, decreases to approximately 4.0, then plateaus.
* **2M (Red):** Starts around 5.6, decreases to approximately 3.8, then plateaus.
* **3M (Light Red):** Starts around 5.4, decreases to approximately 3.6, then plateaus.
* **200M (Very Light Red):** Starts around 5.2, decreases to approximately 3.2, then plateaus.
* **300M (Lightest Red):** Starts around 5.0, decreases to approximately 2.8, then plateaus.
* All lines show a decrease in Test Loss up to approximately 10<sup>2</sup> (100) Token Index in Context, after which they plateau.
### Key Observations
* Transformers consistently outperform LSTMs across all parameter sizes in the left chart.
* LSTMs exhibit diminishing returns with increasing parameters, while Transformers continue to improve.
* LSTMs show a clear plateau effect in the right chart, indicating limited ability to leverage longer contexts.
* Transformers continue to improve with increasing context length in the right chart.
* Increasing the number of parameters in both models generally leads to lower Test Loss, but the effect is more pronounced for Transformers.
### Interpretation
The data strongly suggests that Transformers are superior to LSTMs, particularly when dealing with long-range dependencies in data. The asymptotic improvement of Transformers with increasing parameters indicates a greater capacity to model complex relationships. The plateauing of LSTMs, both in terms of parameters and context length, highlights their limitations in handling long sequences. The right chart visually demonstrates the core advantage of Transformers: their ability to effectively utilize information from a wider context window, leading to improved performance. The logarithmic scales on both axes suggest that the benefits of Transformers are particularly significant at larger scales (more parameters, longer contexts). The difference in performance is not merely a matter of scale; the fundamental architecture of Transformers allows them to overcome the vanishing gradient problem that plagues LSTMs when processing long sequences.