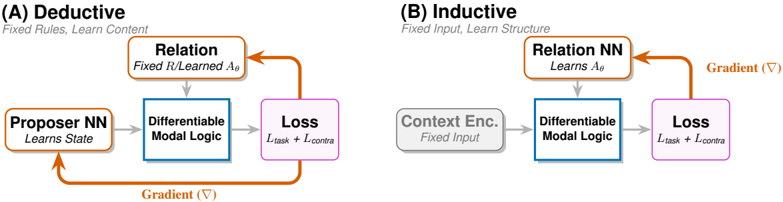
## Diagram: Deductive vs. Inductive Neural Network Architectures
### Overview
The image compares two neural network architectures: **Deductive** (A) and **Inductive** (B). Both involve a **Differentiable Modal Logic** component and a **Loss** function, but differ in their structural design principles and learning objectives.
### Components/Axes
#### (A) Deductive
- **Title**: "Deductive"
- **Subtitle**: "Fixed Rules, Learn Content"
- **Components**:
1. **Proposer NN**: "Learns State" (orange box with bidirectional arrow).
2. **Relation**: "Fixed R/Learned Aθ" (orange box with unidirectional arrow to Differentiable Modal Logic).
3. **Differentiable Modal Logic**: Central blue box with gradient (∇) annotation.
4. **Loss**: "L_task + L_contra" (purple box).
- **Flow**:
- Proposer NN → Relation → Differentiable Modal Logic → Loss.
- Gradient (∇) flows from Loss back to Proposer NN.
#### (B) Inductive
- **Title**: "Inductive"
- **Subtitle**: "Fixed Input, Learn Structure"
- **Components**:
1. **Context Enc.**: "Fixed Input" (gray box with unidirectional arrow).
2. **Relation NN**: "Learns Aθ" (orange box with unidirectional arrow to Differentiable Modal Logic).
3. **Differentiable Modal Logic**: Central blue box (shared with Deductive).
4. **Loss**: "L_task + L_contra" (purple box).
- **Flow**:
- Context Enc. → Relation NN → Differentiable Modal Logic → Loss.
- Gradient (∇) flows from Loss back to Relation NN.
### Detailed Analysis
- **Deductive Architecture**:
- **Proposer NN** learns the system state, suggesting dynamic adaptation.
- **Relation** combines fixed rules (R) with learned parameters (Aθ), indicating hybrid reasoning.
- Gradient (∇) propagates through the entire loop, enabling end-to-end training.
- **Inductive Architecture**:
- **Context Enc.** processes fixed input data, emphasizing structured input handling.
- **Relation NN** learns parameters (Aθ) directly, focusing on structural adaptation.
- Gradient (∇) is localized to the Relation NN and Loss, limiting backpropagation scope.
### Key Observations
1. **Shared Elements**:
- Both architectures use **Differentiable Modal Logic** as a core component.
- Loss function combines task-specific (L_task) and contrastive (L_contra) objectives.
2. **Divergent Designs**:
- **Deductive** prioritizes learning content (state) while retaining fixed rules.
- **Inductive** focuses on learning structure (Aθ) from fixed inputs.
3. **Gradient Flow**:
- Deductive uses a closed-loop gradient (∇) for holistic optimization.
- Inductive restricts gradients to the Relation NN and Loss, simplifying training.
### Interpretation
The diagram illustrates a trade-off between **rule-based reasoning** (Deductive) and **data-driven adaptation** (Inductive). The Deductive approach leverages fixed rules for stability while learning state-specific content, whereas the Inductive method optimizes structural parameters (Aθ) to generalize from fixed inputs. The shared use of Differentiable Modal Logic suggests a unified framework for integrating symbolic reasoning with neural learning. The gradient annotations highlight differences in optimization strategies, with Deductive favoring global updates and Inductive focusing on localized parameter tuning.