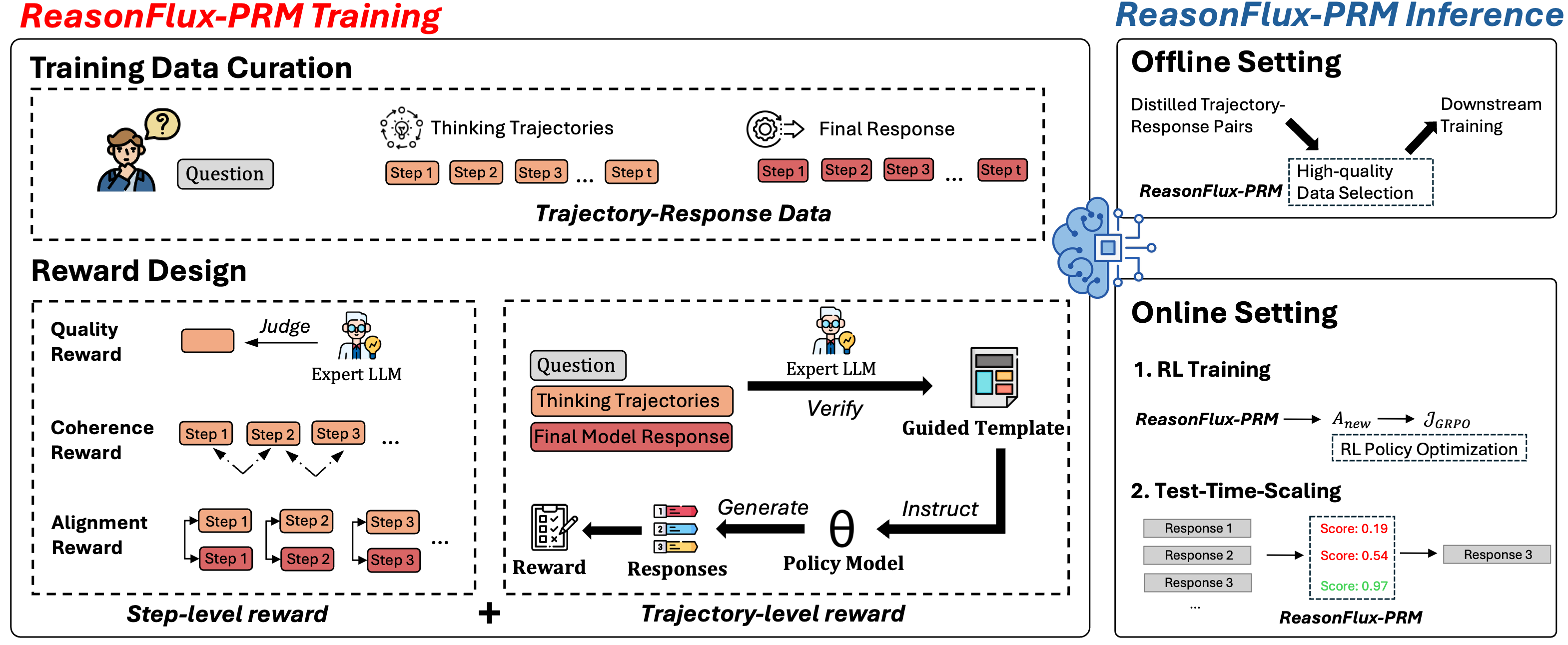
## Diagram: ReasonFlux-PRM Training and Inference Process
### Overview
The diagram illustrates the workflow of ReasonFlux-PRM, a system combining offline and online training phases with reward-based optimization. It emphasizes trajectory-response data curation, multi-level reward design, and test-time scaling for response selection.
### Components/Axes
1. **Training Data Curation**
- Input: Question → Thinking Trajectories (Step 1 → Step t) → Final Response
- Output: Trajectory-Response Data
- Visual elements: Person icon with question bubble, circular thinking trajectory arrows, gear icon for final response
2. **Reward Design**
- Three reward types:
- **Quality Reward**: Judge (Expert LLM) evaluates final response
- **Coherence Reward**: Step-level alignment between trajectory steps
- **Alignment Reward**: Step-level consistency with expert LLM guidance
- Visual elements: Judge icon, step progression arrows, color-coded reward boxes (orange/red)
3. **Offline Setting**
- Process: Distilled Trajectory-Response Pairs → High-quality Data Selection → Downstream Training
- Visual elements: Brain icon with neural network, dashed box for data selection
4. **Online Setting**
- **1. RL Training**: ReasonFlux-PRM → A_new → J_GRPO (RL Policy Optimization)
- **2. Test-Time Scaling**: Three response options with scores (0.19, 0.54, 0.97) → Selected Response
- Visual elements: Score boxes with color gradients (red/yellow/green), selection arrow
### Detailed Analysis
- **Training Phase**:
- Trajectory-Response Data is generated through iterative thinking steps (Step 1 → Step t)
- Reward signals combine expert LLM judgments (Quality) and step-level coherence (Coherence/Alignment)
- Color coding: Orange for trajectory steps, red for final responses
- **Inference Phase**:
- Offline: High-quality data selection filters trajectory-response pairs
- Online: RL training optimizes policy (A_new) using GRPO, while test-time scaling evaluates multiple responses
- Test-Time Scoring: Three responses with confidence scores (0.19, 0.54, 0.97) demonstrate progressive selection
### Key Observations
1. **Reward Integration**: Step-level rewards (Coherence/Alignment) feed into trajectory-level optimization
2. **Expert LLM Role**: Appears in both training (Judge) and inference (Verification) phases
3. **Score Distribution**: Test-time scores show clear preference pattern (0.19 < 0.54 < 0.97)
4. **Flow Direction**: Left-to-right progression from data curation to inference
### Interpretation
The diagram reveals a hybrid approach combining:
1. **Offline Pre-training**: Expert knowledge distillation through trajectory curation
2. **Online Adaptation**: Real-time response optimization using RL and test-time scaling
3. **Multi-level Rewards**: Ensures both step-by-step reasoning quality and final response effectiveness
Notable patterns:
- The system prioritizes high-confidence responses (0.97 score) through test-time scaling
- Expert LLM serves dual roles: quality assessment during training and verification during inference
- Color coding (orange/red/yellow/green) visually distinguishes process stages and confidence levels
This architecture suggests a focus on maintaining reasoning quality through both pre-training curation and real-time adaptive selection, with explicit mechanisms for handling uncertainty in response generation.