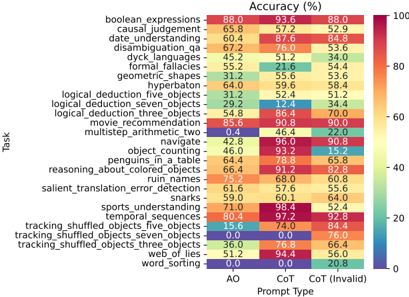
\n
## Heatmap: Accuracy of Large Language Models on Various Tasks
### Overview
This image presents a heatmap visualizing the accuracy (%) of a large language model across 22 different tasks, evaluated under three different prompt types: AO (presumably "Automatic Operation"), CoT ("Chain of Thought"), and CoT (Invalid). The accuracy is represented by color, with a gradient from blue (low accuracy) to red (high accuracy). The tasks are listed vertically on the y-axis, and the prompt types are listed horizontally on the x-axis.
### Components/Axes
* **Y-axis (Tasks):** Lists the following tasks:
* boolean expressions
* causal judgement
* date understanding
* disambiguation_qa
* dyck languages
* formal fallacies
* geometric_shapes
* hyperberon
* logical deduction_five_objects
* logical deduction_seven_objects
* logical_deduction_three_objects
* movie recommendation
* multistep_arithmetic_two
* navigate
* object counting
* penguins_in_a_table
* reasoning_about_colored_objects
* ruin names
* salient_translation_error_detection
* snarks
* sports understanding
* temporal sequences
* tracking_shuffled_objects_five_objects
* tracking_shuffled_objects_seven_objects
* tracking_shuffled_objects_three_objects
* web_of_lies
* word_sorting
* **X-axis (Prompt Type):** Categorized into three prompt types:
* AO (Purple)
* CoT (Orange)
* CoT (Invalid) (Green)
* **Color Scale:** Represents accuracy percentage, ranging from approximately 0% (dark blue) to 100% (dark red). The scale is marked at 0, 20, 40, 60, 80, and 100.
* **Title:** "Accuracy (%)" positioned at the top-center of the heatmap.
### Detailed Analysis
The heatmap displays accuracy values for each task and prompt type combination. Here's a breakdown of some key values (approximate, based on color mapping):
* **boolean expressions:** AO: 88.0%, CoT: 93.6%, CoT (Invalid): 88.0%
* **causal judgement:** AO: 57.2%, CoT: 65.8%, CoT (Invalid): 52.9%
* **date understanding:** AO: 87.6%, CoT: 84.8%, CoT (Invalid): 60.4%
* **disambiguation_qa:** AO: 67.2%, CoT: 76.0%, CoT (Invalid): 33.6%
* **dyck languages:** AO: 45.2%, CoT: 34.0%, CoT (Invalid): 44.0%
* **formal fallacies:** AO: 55.2%, CoT: 21.6%, CoT (Invalid): 45.3%
* **geometric_shapes:** AO: 64.0%, CoT: 59.6%, CoT (Invalid): 58.4%
* **hyperberon:** AO: 64.0%, CoT: 59.6%, CoT (Invalid): 58.4%
* **logical deduction_five_objects:** AO: 31.2%, CoT: 52.4%, CoT (Invalid): 51.2%
* **logical deduction_seven_objects:** AO: 29.2%, CoT: 12.4%, CoT (Invalid): 34.4%
* **logical_deduction_three_objects:** AO: 54.8%, CoT: 86.4%, CoT (Invalid): 70.0%
* **movie recommendation:** AO: 85.6%, CoT: 90.8%, CoT (Invalid): 90.0%
* **multistep_arithmetic_two:** AO: 0.4%, CoT: 46.4%, CoT (Invalid): 22.0%
* **navigate:** AO: 42.8%, CoT: 96.0%, CoT (Invalid): 96.8%
* **object counting:** AO: 64.4%, CoT: 78.8%, CoT (Invalid): 65.8%
* **reasoning_about_colored_objects:** AO: 66.4%, CoT: 91.2%, CoT (Invalid): 82.8%
* **ruin names:** AO: 75.2%, CoT: 96.0%, CoT (Invalid): 96.4%
* **salient_translation_error_detection:** AO: 59.6%, CoT: 60.1%, CoT (Invalid): 59.0%
* **snarks:** AO: 61.0%, CoT: 60.1%, CoT (Invalid): 61.0%
* **sports understanding:** AO: 71.0%, CoT: 98.4%, CoT (Invalid): 52.4%
* **temporal sequences:** AO: 70.8%, CoT: 94.4%, CoT (Invalid): 92.8%
* **tracking_shuffled_objects_five_objects:** AO: 0.0%, CoT: 74.0%, CoT (Invalid): 76.0%
* **tracking_shuffled_objects_seven_objects:** AO: 15.6%, CoT: 40.0%, CoT (Invalid): 84.4%
* **tracking_shuffled_objects_three_objects:** AO: 36.0%, CoT: 90.8%, CoT (Invalid): 60.8%
* **web_of_lies:** AO: 61.0%, CoT: 66.0%, CoT (Invalid): 66.0%
* **word_sorting:** AO: 46.8%, CoT: 84.0%, CoT (Invalid): 70.0%
**Trends:**
* Generally, CoT prompts yield higher accuracy than AO prompts.
* CoT (Invalid) prompts show variable accuracy, sometimes performing better than AO, sometimes worse than CoT.
* Some tasks (e.g., navigate, ruin names, sports understanding) consistently achieve high accuracy with CoT prompts.
* Tasks like multistep\_arithmetic\_two and tracking\_shuffled\_objects\_five\_objects have very low accuracy with AO prompts.
### Key Observations
* The "navigate" task shows nearly perfect accuracy with both CoT and CoT (Invalid) prompts.
* "multistep\_arithmetic\_two" is a particularly challenging task for the model, with extremely low accuracy under the AO prompt.
* The performance difference between prompt types is most pronounced for tasks like "logical deduction\_seven\_objects" and "multistep\_arithmetic\_two".
* The CoT (Invalid) prompt type sometimes outperforms AO, suggesting that even flawed CoT prompts can be beneficial.
### Interpretation
This heatmap demonstrates the significant impact of prompt engineering (specifically, the use of Chain of Thought prompting) on the performance of large language models across a diverse set of reasoning tasks. The consistent improvement observed with CoT prompts suggests that guiding the model to articulate its reasoning process enhances its ability to solve complex problems. The variability in performance with the "CoT (Invalid)" prompt type highlights the sensitivity of these models to prompt quality and structure. The tasks where AO performs poorly but CoT performs well indicate areas where the model benefits most from explicit reasoning guidance. The heatmap provides valuable insights for optimizing prompt design and understanding the strengths and weaknesses of these models in different reasoning scenarios. The data suggests that while LLMs have made strides in reasoning, they still struggle with tasks requiring complex arithmetic or tracking multiple objects, even with CoT prompting.