## Line Charts: Accuracy vs. Sequence Length and Training Steps for KDA, GDN, and Mamba2
### Overview
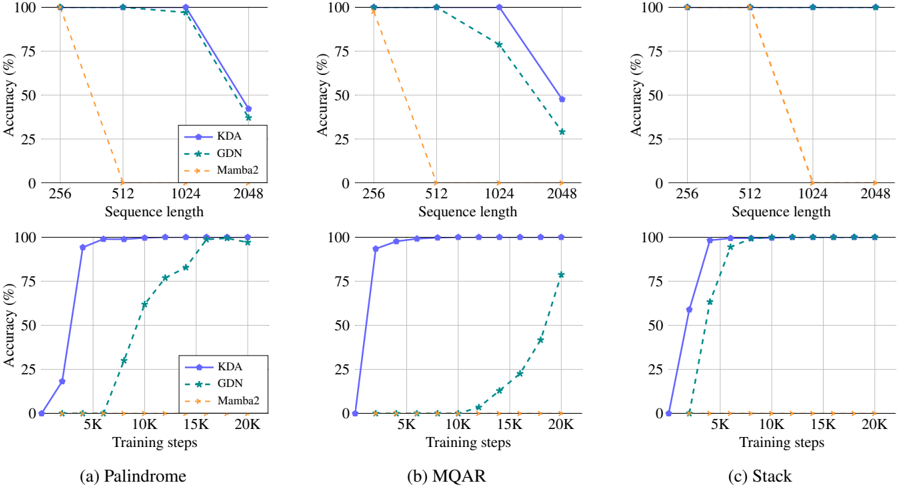
The image presents six line charts arranged in a 2x3 grid. Each column represents a different task: Palindrome, MQAR, and Stack. The top row shows accuracy (%) versus sequence length, while the bottom row shows accuracy (%) versus training steps. The charts compare the performance of three models: KDA (solid blue line), GDN (dashed green line with star markers), and Mamba2 (dashed orange line).
### Components/Axes
**General Chart Elements:**
* **Title:** Each column has a title at the bottom: (a) Palindrome, (b) MQAR, (c) Stack.
* **Y-axis:** Labeled "Accuracy (%)" with ticks at 0, 25, 50, 75, and 100.
* **Legend:** Located in the top-left chart of the first column, indicating:
* KDA: Solid blue line
* GDN: Dashed green line with star markers
* Mamba2: Dashed orange line
**Top Row (Accuracy vs. Sequence Length):**
* **X-axis:** Labeled "Sequence length" with ticks at 256, 512, 1024, and 2048.
**Bottom Row (Accuracy vs. Training Steps):**
* **X-axis:** Labeled "Training steps" with ticks at 5K, 10K, 15K, and 20K.
### Detailed Analysis
**1. Palindrome (Column a):**
* **Top Chart (Sequence Length):**
* KDA (blue): Accuracy is 100% at sequence lengths 256, 512, and 1024, then drops to approximately 42% at 2048.
* GDN (green): Accuracy is 100% at sequence lengths 256, 512, and 1024, then drops to approximately 28% at 2048.
* Mamba2 (orange): Accuracy starts at 100% at 256, drops to 0% at 512, and remains at 0% for 1024 and 2048.
* **Bottom Chart (Training Steps):**
* KDA (blue): Accuracy increases sharply from 0% at 0K to approximately 95% at 5K, then reaches 100% and remains constant.
* GDN (green): Accuracy increases from 0% at 0K to approximately 60% at 15K, then reaches approximately 95% at 20K.
* Mamba2 (orange): Accuracy remains at 0% for all training steps.
**2. MQAR (Column b):**
* **Top Chart (Sequence Length):**
* KDA (blue): Accuracy is 100% at sequence lengths 256, 512, and 1024, then drops to approximately 48% at 2048.
* GDN (green): Accuracy is 100% at sequence lengths 256, 512, and 1024, then drops to approximately 25% at 2048.
* Mamba2 (orange): Accuracy starts at 100% at 256, drops to 0% at 512, and remains at 0% for 1024 and 2048.
* **Bottom Chart (Training Steps):**
* KDA (blue): Accuracy increases sharply from 0% at 0K to approximately 95% at 5K, then reaches 100% and remains constant.
* GDN (green): Accuracy increases slowly from 0% at 0K to approximately 75% at 20K.
* Mamba2 (orange): Accuracy remains at 0% for all training steps.
**3. Stack (Column c):**
* **Top Chart (Sequence Length):**
* KDA (blue): Accuracy is 100% for all sequence lengths.
* GDN (green): Accuracy is 100% for all sequence lengths.
* Mamba2 (orange): Accuracy starts at 100% at 256, drops to 0% at 512, and remains at 0% for 1024 and 2048.
* **Bottom Chart (Training Steps):**
* KDA (blue): Accuracy increases sharply from 0% at 0K to 100% at 5K, and remains constant.
* GDN (green): Accuracy increases sharply from 0% at 0K to approximately 98% at 5K, and remains constant.
* Mamba2 (orange): Accuracy remains at 0% for all training steps.
### Key Observations
* KDA and GDN generally perform well with shorter sequence lengths, but their accuracy decreases as the sequence length increases to 2048, except for the Stack task where they maintain 100% accuracy.
* Mamba2 consistently drops to 0% accuracy after a sequence length of 256 for all tasks.
* For all tasks, KDA reaches 100% accuracy with fewer training steps compared to GDN.
* Mamba2 does not improve with increased training steps and remains at 0% accuracy.
### Interpretation
The charts demonstrate the performance of KDA, GDN, and Mamba2 models on different tasks (Palindrome, MQAR, Stack) under varying sequence lengths and training steps. The results suggest that:
* KDA is generally more efficient in terms of training steps to achieve high accuracy.
* GDN requires more training steps to reach comparable accuracy to KDA.
* Mamba2 is not suitable for these tasks, as its accuracy drops to 0% with longer sequence lengths and does not improve with increased training.
* The Stack task is relatively easier for KDA and GDN, as they achieve 100% accuracy even with shorter training steps and maintain it across all sequence lengths.
* The performance of KDA and GDN degrades with longer sequence lengths for Palindrome and MQAR tasks, indicating potential limitations in handling longer sequences for these specific tasks.