\n
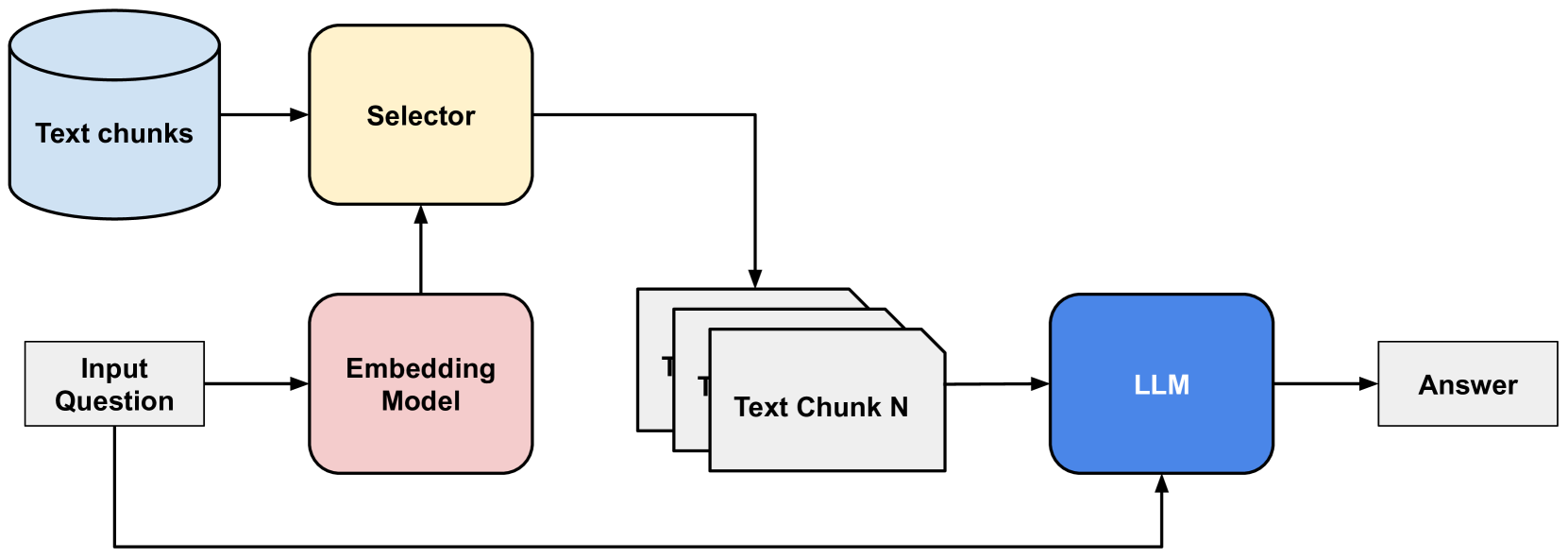
## Diagram: Retrieval Augmented Generation (RAG) Pipeline
### Overview
The image depicts a diagram illustrating a Retrieval Augmented Generation (RAG) pipeline. This pipeline combines information retrieval with a Large Language Model (LLM) to generate answers to input questions. The diagram shows the flow of data from an input question, through embedding, selection of relevant text chunks, and finally to the LLM for answer generation.
### Components/Axes
The diagram consists of the following components:
* **Input Question:** A rectangular box labeled "Input Question".
* **Embedding Model:** A rectangular box labeled "Embedding Model".
* **Selector:** A rectangular box labeled "Selector".
* **Text Chunks:** A cylindrical shape labeled "Text chunks" and a stack of rectangular boxes labeled "Text Chunk 1" through "Text Chunk N".
* **LLM:** A rectangular box labeled "LLM".
* **Answer:** A rectangular box labeled "Answer".
Arrows indicate the flow of data between these components.
### Detailed Analysis or Content Details
The data flow is as follows:
1. An "Input Question" is fed into an "Embedding Model".
2. The "Embedding Model" processes the question and sends its output to the "Selector".
3. The "Selector" also receives input from "Text chunks".
4. The "Selector" identifies and retrieves relevant "Text Chunk(s)" (from "Text Chunk 1" to "Text Chunk N") based on the embedded question.
5. The selected "Text Chunk(s)" and the original "Input Question" are fed into the "LLM".
6. The "LLM" processes this combined information and generates an "Answer".
There are no numerical values or scales present in the diagram. The diagram is purely conceptual, illustrating the process flow.
### Key Observations
The diagram highlights the key stages of a RAG pipeline: embedding, retrieval, and generation. The "Selector" component is central to the process, acting as the bridge between the knowledge base ("Text chunks") and the LLM. The diagram emphasizes that the LLM doesn't operate solely on its pre-trained knowledge but is augmented with retrieved information.
### Interpretation
This diagram illustrates a common architecture for building question-answering systems using LLMs. The RAG approach addresses the limitations of LLMs by providing them with access to external knowledge sources. This allows the LLM to generate more accurate and contextually relevant answers. The "Embedding Model" transforms the question and text chunks into vector representations, enabling semantic similarity search by the "Selector". The "Selector" then identifies the most relevant text chunks to provide to the LLM. This process is crucial for mitigating the problem of LLMs generating incorrect or outdated information (hallucinations). The diagram suggests a modular design, where each component can be independently developed and optimized. The "N" in "Text Chunk N" indicates that the system can handle a variable number of text chunks, suggesting scalability.