\n
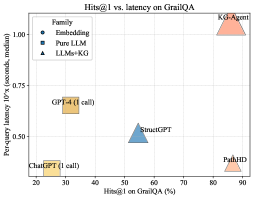
## Scatter Plot: Hits@1 vs. Latency on GrailQA
### Overview
This scatter plot visualizes the relationship between Hits@1 on GrailQA (percentage) and per-query latency (seconds, median) for several different models. The models are categorized by their "Family" – Embedding, Pure LLM, and LLMs+KG.
### Components/Axes
* **X-axis:** Hits@1 on GrailQA (%). Scale ranges from approximately 20% to 90%.
* **Y-axis:** Per-query latency 10x (seconds, median). Scale ranges from approximately 0.25 seconds to 1.0 seconds.
* **Legend:** Located in the top-left corner, categorizes models by "Family":
* **Embedding (Blue Circles):** Represents models using embedding techniques.
* **Pure LLM (Blue Squares):** Represents models that are purely Large Language Models.
* **LLMs+KG (Orange Triangles):** Represents models combining Large Language Models with Knowledge Graphs.
* **Data Points:** Each point represents a specific model, plotted based on its Hits@1 and latency.
### Detailed Analysis
Here's a breakdown of the data points, referencing the legend colors for verification:
* **KG-Agent (Orange Triangle):** Located at approximately (85%, 1.0 seconds).
* **PathHD (Orange Triangle):** Located at approximately (90%, 0.95 seconds).
* **StructGPT (Blue Square):** Located at approximately (55%, 0.5 seconds).
* **GPT-4 (1 call) (Yellow Square):** Located at approximately (30%, 0.63 seconds).
* **ChatGPT (1 call) (Yellow Square):** Located at approximately (20%, 0.3 seconds).
### Key Observations
* **Trade-off:** There appears to be a general trade-off between Hits@1 and latency. Models with higher Hits@1 tend to have higher latency.
* **KG-based Models:** The LLMs+KG models (KG-Agent and PathHD) achieve the highest Hits@1 scores but also exhibit the highest latency.
* **Pure LLM:** StructGPT has a moderate Hits@1 score and moderate latency.
* **Embedding Models:** No embedding models are present in the plot.
* **GPT-4 and ChatGPT:** These models have the lowest Hits@1 scores but also the lowest latency.
### Interpretation
The data suggests that incorporating Knowledge Graphs (KGs) into LLMs can significantly improve the accuracy (Hits@1) of responses on the GrailQA dataset, but at the cost of increased processing time (latency). The models leveraging KGs (KG-Agent and PathHD) demonstrate this trade-off clearly.
The positioning of GPT-4 and ChatGPT indicates they prioritize speed over accuracy in this context. StructGPT represents a middle ground, offering a balance between the two.
The absence of embedding models from the plot is notable. It could indicate that these models were not tested in this specific evaluation, or that their performance was not competitive with the other approaches.
The "1 call" annotation next to GPT-4 and ChatGPT suggests that the latency measurements are for a single API call, which might not fully represent the end-to-end latency of a more complex application. The use of "median" latency suggests an attempt to mitigate the impact of outliers, but further analysis of the latency distribution would be beneficial.