## Data Table: Model Performance Across Categories
### Overview
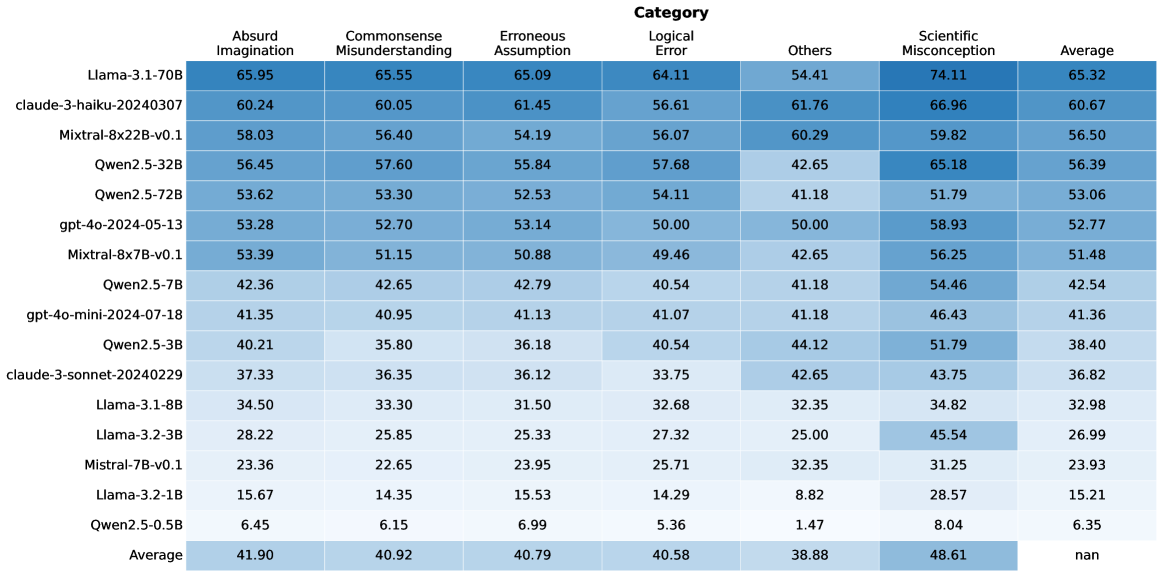
The image displays a data table that presents performance scores for various language models across different categories of evaluation. The table lists specific model names on the left-hand side and evaluation categories as column headers. Numerical values, likely representing scores or percentages, are presented within the cells, with a color gradient indicating relative performance within each column. An "Average" row at the bottom summarizes the performance across all listed models for each category.
### Components/Axes
**Row Headers (Model Names):**
* Llama-3.1-70B
* claude-3-haiku-20240307
* Mistral-8x22B-v0.1
* Qwen2.5-32B
* Qwen2.5-72B
* gpt-4o-2024-05-13
* Mistral-8x7B-v0.1
* Qwen2.5-7B
* gpt-4o-mini-2024-07-18
* Qwen2.5-3B
* claude-3-sonnet-20240229
* Llama-3.1-8B
* Llama-3.2-3B
* Mistral-7B-v0.1
* Llama-3.2-1B
* Qwen2.5-0.5B
* Average
**Column Headers (Categories):**
* Absurd Imagination
* Commonsense Misunderstanding
* Erroneous Assumption
* Logical Error
* Others
* Scientific Misconception
* Average
**Data Cells:** Numerical values ranging from approximately 6.45 to 74.11. The "Average" column for the "Average" row contains "nan" (not a number), indicating no average could be computed for this specific cell.
### Detailed Analysis
The table contains numerical data for each model under each category. The values are presented with two decimal places.
**Row-wise Data (Selected Examples):**
* **Llama-3.1-70B:**
* Absurd Imagination: 65.95
* Commonsense Misunderstanding: 65.55
* Erroneous Assumption: 65.09
* Logical Error: 64.11
* Others: 54.41
* Scientific Misconception: 74.11
* Average: 65.32
* **claude-3-haiku-20240307:**
* Absurd Imagination: 60.24
* Commonsense Misunderstanding: 60.05
* Erroneous Assumption: 61.45
* Logical Error: 56.61
* Others: 61.76
* Scientific Misconception: 66.96
* Average: 60.67
* **Mistral-8x22B-v0.1:**
* Absurd Imagination: 58.03
* Commonsense Misunderstanding: 56.40
* Erroneous Assumption: 54.19
* Logical Error: 56.07
* Others: 60.29
* Scientific Misconception: 59.82
* Average: 56.50
* **Qwen2.5-0.5B:**
* Absurd Imagination: 6.45
* Commonsense Misunderstanding: 6.15
* Erroneous Assumption: 6.99
* Logical Error: 5.36
* Others: 1.47
* Scientific Misconception: 8.04
* Average: 6.35
**Column-wise Data (Averages):**
* **Absurd Imagination (Average):** 41.90
* **Commonsense Misunderstanding (Average):** 40.92
* **Erroneous Assumption (Average):** 40.79
* **Logical Error (Average):** 40.58
* **Others (Average):** 38.88
* **Scientific Misconception (Average):** 48.61
* **Average (Average):** nan
**Color Gradient Analysis:**
The table uses a blue color gradient. Lighter shades of blue generally correspond to lower numerical values, while darker shades correspond to higher numerical values within each column. This visually highlights the best and worst performing models for each specific category. For example, in the "Scientific Misconception" column, "Llama-3.1-70B" (74.11) is the darkest blue, indicating the highest score, while "Qwen2.5-0.5B" (8.04) is the lightest, indicating the lowest score.
### Key Observations
* **Top Performer:** "Llama-3.1-70B" consistently scores the highest across most categories, particularly in "Scientific Misconception" (74.11) and "Absurd Imagination" (65.95).
* **Lowest Performer:** "Qwen2.5-0.5B" consistently scores the lowest across all categories, with values generally below 10.
* **Category Performance:** "Scientific Misconception" appears to be a category where models generally score higher on average (48.61) compared to other categories like "Others" (38.88) or "Logical Error" (40.58).
* **Model Consistency:** Some models, like "Llama-3.1-70B" and "claude-3-haiku-20240307", show relatively high scores across multiple categories. Others, like "Qwen2.5-7B" and "gpt-4o-mini-2024-07-18", have scores in the low 40s for most categories.
* **Outlier in Averages:** The "Average" column for the "Average" row shows "nan", which is expected as it represents the average of averages, and the "Average" column itself is a summary metric.
### Interpretation
This data table likely represents an evaluation of different language models' capabilities in handling various types of prompts or questions. The categories suggest different cognitive or reasoning challenges:
* **"Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," and "Logical Error"** likely assess a model's ability to understand and reason about non-factual or flawed information, or to identify and correct logical inconsistencies.
* **"Others"** is a more general category, possibly encompassing a range of tasks not specifically defined by the other categories.
* **"Scientific Misconception"** specifically tests the model's knowledge and ability to avoid or correct factual errors related to scientific concepts.
The consistently high scores of "Llama-3.1-70B" suggest it is a very capable model, particularly in areas requiring factual accuracy (Scientific Misconception) and potentially in understanding complex or unusual scenarios (Absurd Imagination). The low scores of "Qwen2.5-0.5B" indicate it is significantly less performant across the board.
The fact that "Scientific Misconception" has the highest average score across all models might imply that current language models are generally better at recalling and applying factual scientific knowledge than they are at navigating nuanced or flawed reasoning scenarios. Conversely, the "Others" category having the lowest average suggests it might be the most challenging or diverse set of tasks.
The presence of specific model versions (e.g., "Llama-3.1-70B", "claude-3-haiku-20240307") and dates (e.g., "gpt-4o-2024-05-13") indicates a comparative analysis of contemporary language models, likely to benchmark their strengths and weaknesses. The data allows for a granular understanding of which models excel in specific areas, which could inform their deployment for particular applications. For instance, a model performing well in "Logical Error" might be preferred for tasks requiring critical analysis, while one strong in "Scientific Misconception" would be better for knowledge-based queries.