\n
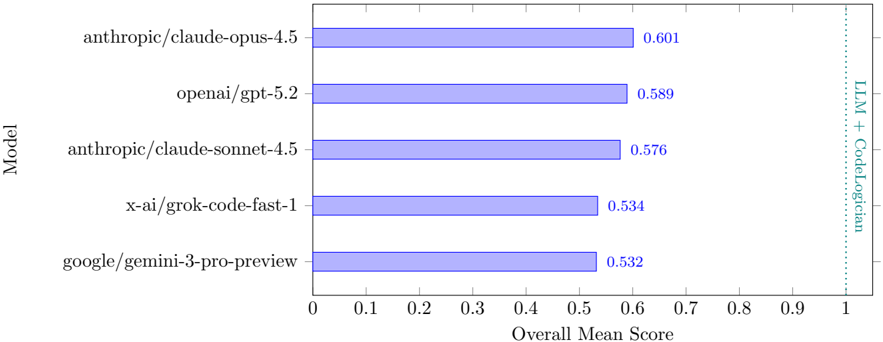
## Horizontal Bar Chart: LLM + CodeLogician Performance Comparison
### Overview
This is a horizontal bar chart comparing the "Overall Mean Score" of five different Large Language Models (LLMs) on a task involving both language modeling and code logic. The chart displays the models ranked by their scores, with higher scores indicating better performance.
### Components/Axes
* **Y-axis (Vertical):** Labeled "Model". The categories are:
* anthropic/claude-opus-4.5
* openai/gpt-5.2
* anthropic/claude-sonnet-4.5
* x-ai/grok-code-fast-1
* google/gemini-3-pro-preview
* **X-axis (Horizontal):** Labeled "Overall Mean Score". The scale ranges from 0 to 1, with tick marks at 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.
* **Bars:** Each bar represents a model, with its length corresponding to its "Overall Mean Score". The bars are a light blue color.
* **Annotation:** A vertical dashed line is present at x=1, with the text "LLM + CodeLogician" to the right of the line.
### Detailed Analysis
The bars are arranged from top to bottom in descending order of their scores.
* **anthropic/claude-opus-4.5:** The bar extends to approximately 0.601.
* **openai/gpt-5.2:** The bar extends to approximately 0.589.
* **anthropic/claude-sonnet-4.5:** The bar extends to approximately 0.576.
* **x-ai/grok-code-fast-1:** The bar extends to approximately 0.534.
* **google/gemini-3-pro-preview:** The bar extends to approximately 0.532.
The trend is clearly downward as you move down the list of models. The difference between the top two models is small, while the difference between the bottom two is also relatively small.
### Key Observations
* anthropic/claude-opus-4.5 has the highest "Overall Mean Score" at approximately 0.601.
* google/gemini-3-pro-preview has the lowest "Overall Mean Score" at approximately 0.532.
* The scores are relatively close together, suggesting that all models perform reasonably well on this task.
* The annotation "LLM + CodeLogician" suggests that the task involves evaluating the models' ability to handle both language modeling and code-related logic.
### Interpretation
The chart demonstrates a comparison of the performance of several LLMs on a task that requires both language understanding and code reasoning. The scores indicate that anthropic/claude-opus-4.5 is the best performing model, while google/gemini-3-pro-preview is the lowest performing. The relatively small differences in scores suggest that all models are capable, but some are more proficient than others. The annotation "LLM + CodeLogician" implies that the evaluation metric is specifically designed to assess the models' combined abilities in these two areas. The vertical dashed line at 1 could represent a target score or a benchmark for acceptable performance. The chart provides a clear visual representation of the relative strengths and weaknesses of each model in this specific context.