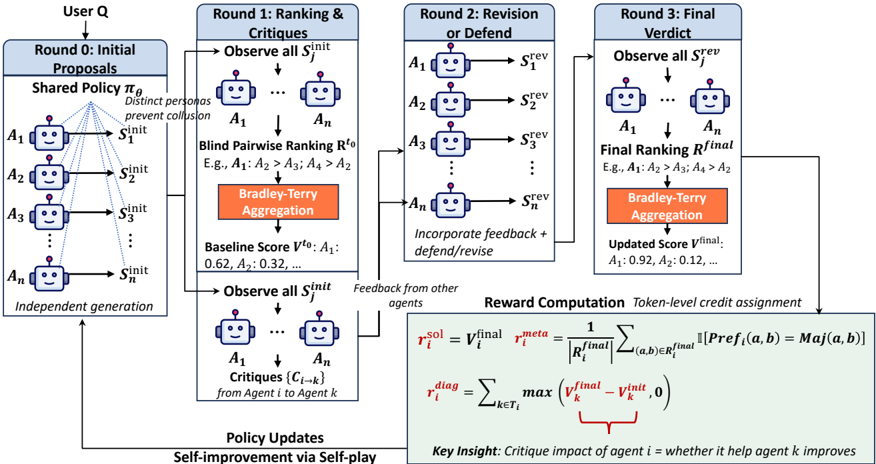
## Process Diagram: Multi-Agent Proposal and Revision
### Overview
The image presents a process diagram illustrating a multi-agent system for proposal generation, ranking, revision, and final verdict. The process involves multiple rounds of interaction among agents, incorporating feedback and self-improvement.
### Components/Axes
* **Header:** Contains the title "User Q" at the top, followed by the round descriptions: "Round 0: Initial Proposals", "Round 1: Ranking & Critiques", "Round 2: Revision or Defend", and "Round 3: Final Verdict".
* **Agents:** Represented by robot icons labeled A1, A2, A3, ..., An.
* **Proposals:** Represented as Sinit, Srev, and Sfinal, indicating initial, revised, and final proposals, respectively.
* **Processes:**
* **Shared Policy πθ:** Used in Round 0. The text "Distinct personas prevent collusion" is associated with this policy.
* **Blind Pairwise Ranking Rto:** Used in Round 1. Example ranking: "E.g., A1: A2 > A3; A4 > A2".
* **Bradley-Terry Aggregation:** Used in Rounds 1 and 3.
* **Critiques {Ci→k}:** From Agent i to Agent k, used in Round 1.
* **Reward Computation:** Token-level credit assignment.
* **Scores:**
* **Baseline Score Vto:** Example values: "A1: 0.62, A2: 0.32, ...".
* **Updated Score Vfinal:** Example values: "A1: 0.92, A2: 0.12, ...".
* **Policy Updates:** "Self-improvement via Self-play" at the bottom-left.
* **Reward Computation Formulas:**
* r_i^{sol} = V_i^{final} * r_i^{meta}
* r_i^{meta} = (1 / |R_i^{final}|) * Σ_{(a,b)∈R_i^{final}} [Pref_i(a, b) = Maj(a, b)]
* r_i^{diag} = Σ_{k∈T_i} max(V_k^{final} - V_k^{init}, 0)
* **Key Insight:** "Critique impact of agent i = whether it help agent k improves"
### Detailed Analysis or Content Details
**Round 0: Initial Proposals**
* User Q initiates the process.
* Agents A1 to An independently generate initial proposals Sinit based on a shared policy πθ.
* The text "Distinct personas prevent collusion" is associated with the shared policy.
**Round 1: Ranking & Critiques**
* Agents observe all initial proposals Sinit.
* Blind pairwise ranking Rto is performed (e.g., A1: A2 > A3; A4 > A2).
* Bradley-Terry Aggregation is applied to the rankings.
* Baseline scores Vto are calculated (e.g., A1: 0.62, A2: 0.32).
* Agents observe all initial proposals Sinit again.
* Agents generate critiques {Ci→k} from Agent i to Agent k.
**Round 2: Revision or Defend**
* Agents A1 to An revise or defend their proposals based on feedback from other agents, resulting in revised proposals Srev.
* The text "Incorporate feedback + defend/revise" is associated with this round.
**Round 3: Final Verdict**
* Agents observe all revised proposals Srev.
* Final ranking Rfinal is performed (e.g., A1: A2 > A3; A4 > A2).
* Bradley-Terry Aggregation is applied to the final rankings.
* Updated scores Vfinal are calculated (e.g., A1: 0.92, A2: 0.12).
**Policy Updates**
* The process includes policy updates through self-improvement via self-play.
* Feedback from other agents is used to update the policies.
**Reward Computation**
* Token-level credit assignment is used for reward computation.
* Formulas are provided for calculating the rewards.
### Key Observations
* The process is iterative, with multiple rounds of proposal generation, ranking, and revision.
* Feedback from other agents plays a crucial role in the revision process.
* The Bradley-Terry Aggregation method is used for ranking aggregation.
* The reward computation formulas provide a quantitative measure of the impact of each agent's critiques.
* The updated scores Vfinal are generally higher than the baseline scores Vto, indicating improvement over the rounds.
### Interpretation
The diagram illustrates a multi-agent system designed to collaboratively generate and refine proposals. The system incorporates mechanisms for ranking, critique, and revision, allowing agents to learn from each other and improve their proposals over time. The use of a shared policy in the initial round ensures a common ground for proposal generation, while the pairwise ranking and Bradley-Terry Aggregation methods provide a robust way to aggregate individual preferences. The reward computation formulas incentivize agents to provide helpful critiques that lead to improved proposals. The overall process promotes self-improvement through self-play, enabling the system to adapt and optimize its performance over time. The increase in scores from baseline to final suggests the system is effective in improving the quality of proposals.