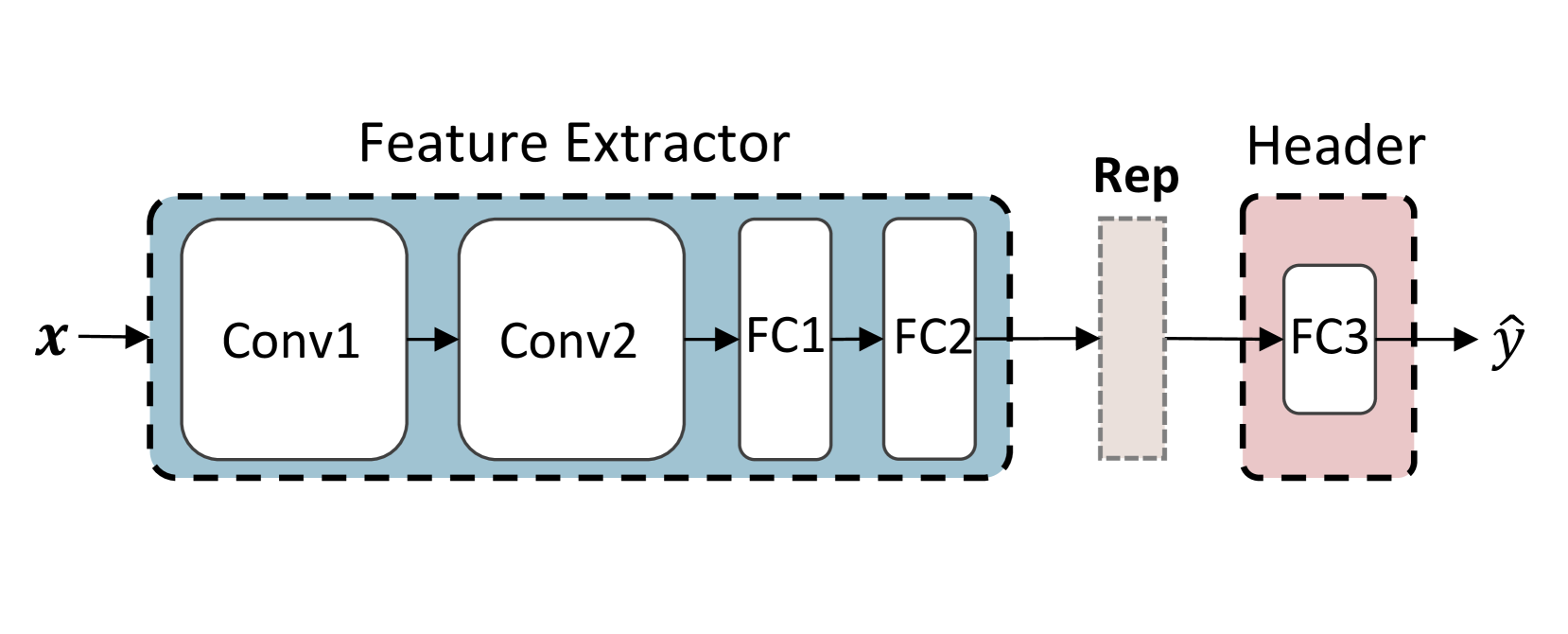
## Diagram: Neural Network Architecture
### Overview
The image displays a block diagram of a feedforward neural network architecture, specifically a convolutional neural network (CNN) followed by fully connected layers. The diagram illustrates the data flow from an input `x` to a predicted output `ŷ`. The architecture is segmented into two primary, visually distinct modules: a "Feature Extractor" and a "Header," with an intermediate representation block labeled "Rep."
### Components/Axes
The diagram is composed of labeled blocks connected by directional arrows indicating data flow from left to right.
**1. Input:**
* **Label:** `x` (italicized, mathematical notation).
* **Position:** Far left, with an arrow pointing into the first block.
**2. Feature Extractor Module:**
* **Container:** A large, light blue rectangle with a dashed black border.
* **Title:** "Feature Extractor" (centered above the container).
* **Internal Components (in sequence):**
* `Conv1`: A rounded rectangle, first layer in the sequence.
* `Conv2`: A rounded rectangle, second layer.
* `FC1`: A narrower, taller rectangle, third layer.
* `FC2`: A narrower, taller rectangle, fourth layer.
* **Flow:** Arrows connect `x` → `Conv1` → `Conv2` → `FC1` → `FC2`.
**3. Intermediate Representation:**
* **Label:** "Rep" (positioned above the block).
* **Component:** A vertical, light gray rectangle with a dashed black border.
* **Position:** Located between the "Feature Extractor" and "Header" modules.
* **Flow:** An arrow connects `FC2` to "Rep," and another arrow connects "Rep" to the next module.
**4. Header Module:**
* **Container:** A smaller, light pink rectangle with a dashed black border.
* **Title:** "Header" (centered above the container).
* **Internal Component:**
* `FC3`: A rounded rectangle inside the Header container.
* **Flow:** An arrow connects "Rep" to `FC3`.
**5. Output:**
* **Label:** `ŷ` (y-hat, italicized, mathematical notation).
* **Position:** Far right, with an arrow pointing out from `FC3`.
### Detailed Analysis
The diagram explicitly defines the network's layer sequence and modular organization.
* **Layer Sequence:** The complete forward pass is: `x` → `Conv1` → `Conv2` → `FC1` → `FC2` → `Rep` → `FC3` → `ŷ`.
* **Module Composition:**
* The **Feature Extractor** contains two convolutional layers (`Conv1`, `Conv2`) followed by two fully connected layers (`FC1`, `FC2`). This suggests it is designed to transform raw input into a high-level feature representation.
* The **Header** contains a single fully connected layer (`FC3`). This is typically the task-specific part of the network (e.g., a classifier or regressor head).
* The **Rep** block is a distinct, unlabeled (beyond "Rep") intermediate stage, likely representing the final feature vector output by the Feature Extractor before it is passed to the Header.
### Key Observations
1. **Modular Design:** The use of dashed-border containers clearly separates the architecture into two main functional modules (Feature Extractor and Header), which is a common pattern in transfer learning or multi-task learning setups.
2. **Layer Type Progression:** The network progresses from convolutional layers (typically for spatial feature extraction) to fully connected layers (for global reasoning and decision-making).
3. **Visual Hierarchy:** The "Feature Extractor" is the largest and most complex component, visually emphasizing its role as the primary processing engine. The "Header" is simpler, indicating it performs a final transformation.
4. **Notation:** Standard mathematical notation (`x`, `ŷ`) is used for input and output. Layer names (`Conv`, `FC`) are standard abbreviations for "Convolutional" and "Fully Connected."
### Interpretation
This diagram represents a standard CNN-based model architecture, likely for an image processing task given the convolutional layers. The clear separation between the **Feature Extractor** and the **Header** is the most significant architectural insight.
* **Functional Relationship:** The Feature Extractor's role is to learn a generic, informative representation (`Rep`) from the input data. The Header's role is to map this generic representation to a specific output prediction (`ŷ`). This decoupling allows for flexibility; the same Feature Extractor could be paired with different Headers for different tasks (e.g., classification vs. detection) by only retraining the Header module.
* **Data Transformation:** The flow shows a transformation from high-dimensional, structured input (like an image) through successive layers that reduce spatial dimensions while increasing feature abstraction (`Conv1` → `Conv2`), followed by a flattening and further processing into a dense feature vector (`FC1` → `FC2` → `Rep`). The final layer (`FC3`) projects this vector into the output space.
* **Implied Context:** The architecture suggests a supervised learning context. The presence of a distinct "Header" often implies that the Feature Extractor may be pre-trained on a large dataset (like ImageNet) and then frozen, while only the Header is trained on a smaller, specific dataset—a common and effective transfer learning strategy. The "Rep" block is the critical interface point for this process.