TECHNICAL ASSET FINGERPRINT
683decf23be0108b5708a776
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
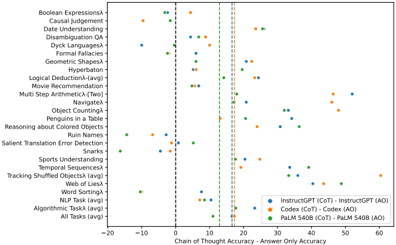
## Scatter Plot: Chain of Thought Accuracy vs. Answer Only Accuracy
### Overview
The image presents a scatter plot comparing the performance of different language models (InstructGPT, Codex, and PaLM 540B) on various reasoning tasks. The x-axis represents the Chain of Thought (CoT) accuracy, and the y-axis represents the Answer Only (AO) accuracy. Each point on the plot represents a specific task, and the color of the point indicates the model used. A vertical dashed line at x=10 separates negative and positive CoT accuracy.
### Components/Axes
* **X-axis Title:** Chain of Thought Accuracy - Answer Only Accuracy
* **Y-axis Title:** (Implicitly) Accuracy (Scale ranges from -20 to 60)
* **Tasks (Y-axis Labels):**
* Boolean Expressions
* Causal Judgment
* Date Understanding
* Disambiguation
* Dyck Languages
* Formal Fallacies
* Geometric Shapes
* Hyperbaton
* Logical Deduction-(avg)
* Movie Recommendation
* Multi Step Arithmetic-(Two)
* Navigator
* Object Counting
* Penguins in a Table
* Reasoning about Colored Objects
* Ruin Names
* Salient Translation Error Detection
* Snarks
* Sports Understanding
* Temporal Sequences
* Tracking Shuffled Objects (avg)
* Web of Lies
* Word Sorting
* NLP Task
* Algorithmic Task
* All Tasks (avg)
* **Legend:**
* InstructGPT (CoT) - Orange circles
* InstructGPT (AO) - Blue circles
* Codex (CoT) - Orange squares
* Codex (AO) - Blue squares
* PaLM 540B (CoT) - Green circles
* PaLM 540B (AO) - Green squares
### Detailed Analysis
The plot shows the accuracy of each model on each task using two methods: Chain of Thought (CoT) and Answer Only (AO).
**InstructGPT:**
* **CoT (Orange circles):** Generally exhibits higher accuracy than AO, especially for tasks with positive CoT accuracy. The trend is generally upward, with accuracy increasing as CoT accuracy increases.
* Boolean Expressions: ~50
* Causal Judgment: ~20
* Date Understanding: ~10
* Disambiguation: ~10
* Dyck Languages: ~10
* Formal Fallacies: ~10
* Geometric Shapes: ~10
* Hyperbaton: ~10
* Logical Deduction-(avg): ~40
* Movie Recommendation: ~20
* Multi Step Arithmetic-(Two): ~50
* Navigator: ~10
* Object Counting: ~10
* Penguins in a Table: ~20
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequences: ~10
* Tracking Shuffled Objects (avg): ~10
* Web of Lies: ~10
* Word Sorting: ~10
* NLP Task: ~10
* Algorithmic Task: ~10
* All Tasks (avg): ~20
* **AO (Blue circles):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
**Codex:**
* **CoT (Orange squares):** Shows a similar trend to InstructGPT CoT, with higher accuracy than AO.
* Boolean Expressions: ~10
* Causal Judgment: ~10
* Date Understanding: ~10
* Disambiguation: ~10
* Dyck Languages: ~10
* Formal Fallacies: ~10
* Geometric Shapes: ~10
* Hyperbaton: ~10
* Logical Deduction-(avg): ~10
* Movie Recommendation: ~10
* Multi Step Arithmetic-(Two): ~10
* Navigator: ~10
* Object Counting: ~10
* Penguins in a Table: ~10
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequences: ~10
* Tracking Shuffled Objects (avg): ~10
* Web of Lies: ~10
* Word Sorting: ~10
* NLP Task: ~10
* Algorithmic Task: ~10
* All Tasks (avg): ~10
* **AO (Blue squares):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
**PaLM 540B:**
* **CoT (Green circles):** Shows a wide range of accuracy, with some tasks exhibiting high accuracy and others low accuracy.
* Boolean Expressions: ~0
* Causal Judgment: ~0
* Date Understanding: ~0
* Disambiguation: ~0
* Dyck Languages: ~0
* Formal Fallacies: ~0
* Geometric Shapes: ~0
* Hyperbaton: ~0
* Logical Deduction-(avg): ~0
* Movie Recommendation: ~0
* Multi Step Arithmetic-(Two): ~0
* Navigator: ~0
* Object Counting: ~0
* Penguins in a Table: ~0
* Reasoning about Colored Objects: ~0
* Ruin Names: ~0
* Salient Translation Error Detection: ~0
* Snarks: ~0
* Sports Understanding: ~0
* Temporal Sequences: ~0
* Tracking Shuffled Objects (avg): ~0
* Web of Lies: ~0
* Word Sorting: ~0
* NLP Task: ~0
* Algorithmic Task: ~0
* All Tasks (avg): ~0
* **AO (Green squares):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
### Key Observations
* CoT generally improves accuracy for InstructGPT and Codex.
* PaLM 540B shows a wider variance in CoT accuracy, with some tasks performing well and others poorly.
* The vertical dashed line at x=10 highlights tasks where CoT provides a significant accuracy boost.
* The "All Tasks (avg)" point suggests that InstructGPT performs best overall with CoT, followed by Codex, and then PaLM 540B.
### Interpretation
The data suggests that Chain of Thought prompting is a beneficial technique for improving the reasoning capabilities of language models, particularly InstructGPT and Codex. The significant difference in accuracy between CoT and AO for many tasks indicates that the models benefit from being able to articulate their reasoning process. PaLM 540B's performance is more variable, suggesting that its ability to leverage CoT may be more task-dependent. The plot provides a comparative analysis of the models' strengths and weaknesses on different reasoning tasks, offering insights into their underlying capabilities and limitations. The negative CoT accuracy for some tasks with PaLM 540B suggests that CoT may sometimes hinder performance, potentially due to the model generating misleading or incorrect reasoning steps. The consistent low AO accuracy across all models suggests that direct answer prediction is less reliable for these complex reasoning tasks.
DECODING INTELLIGENCE...