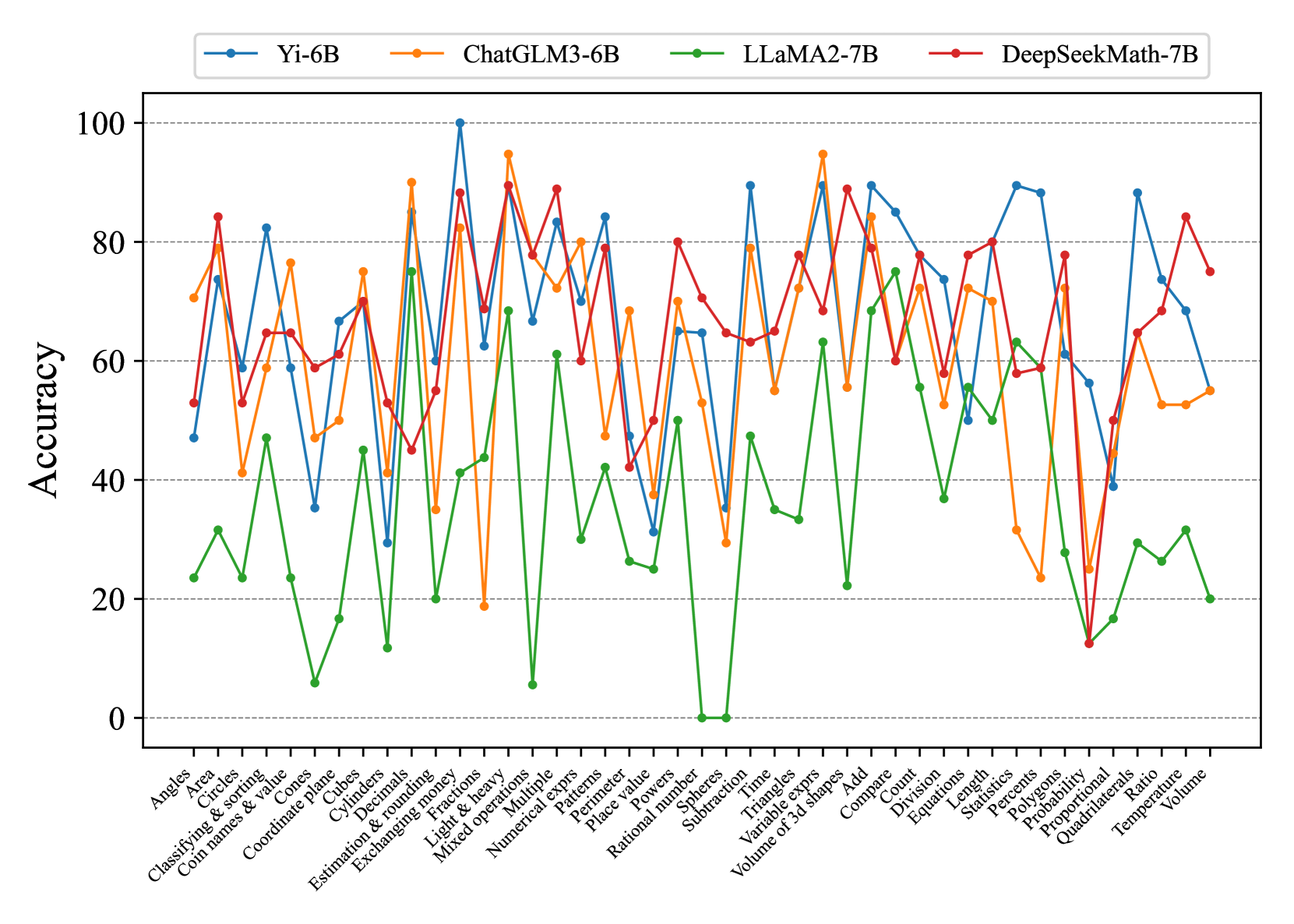
## Line Chart: Model Accuracy on Math Problems
### Overview
The image is a line chart comparing the accuracy of four different language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) on a variety of math-related tasks. The x-axis represents different math problem types, and the y-axis represents the accuracy score (from 0 to 100). Each model's performance is represented by a colored line.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** Represents different math problem types. The labels are:
* Angles
* Area
* Circles
* Classifying & sorting
* Coin names & value
* Cones
* Coordinate plane
* Cubes
* Cylinders
* Decimals
* Estimation & rounding
* Exchanging money
* Fractions
* Light & heavy
* Mixed operations
* Multiple
* Numerical exprs
* Patterns
* Perimeter
* Place value
* Powers
* Rational number
* Spheres
* Subtraction
* Time
* Triangles
* Variable exprs
* Volume of 3d shapes
* Add
* Compare
* Count
* Division
* Equations
* Length
* Percents
* Polygons
* Probability
* Proportional
* Quadrilaterals
* Ratio
* Temperature
* Volume
* **Y-axis:** Represents Accuracy, ranging from 0 to 100 in increments of 20.
* 0
* 20
* 40
* 60
* 80
* 100
* **Legend:** Located at the top of the chart.
* **Blue:** Yi-6B
* **Orange:** ChatGLM3-6B
* **Green:** LLaMA2-7B
* **Red:** DeepSeekMath-7B
* **Gridlines:** Horizontal gridlines are present at each increment of 20 on the y-axis.
### Detailed Analysis
**Yi-6B (Blue):**
* Trend: Fluctuates significantly across different problem types. Generally performs well, often reaching high accuracy, but has some low points.
* Key Data Points:
* Angles: ~50
* Coordinate plane: ~35
* Spheres: ~30
* Volume of 3d shapes: ~65
* Probability: ~90
* Volume: ~55
**ChatGLM3-6B (Orange):**
* Trend: Similar to Yi-6B, fluctuates but generally maintains a relatively high accuracy.
* Key Data Points:
* Angles: ~75
* Coordinate plane: ~80
* Spheres: ~50
* Volume of 3d shapes: ~70
* Probability: ~30
* Volume: ~50
**LLaMA2-7B (Green):**
* Trend: Consistently lower accuracy compared to the other models.
* Key Data Points:
* Angles: ~25
* Coordinate plane: ~10
* Spheres: ~0
* Volume of 3d shapes: ~20
* Probability: ~10
* Volume: ~20
**DeepSeekMath-7B (Red):**
* Trend: Generally high accuracy, often competing with Yi-6B and ChatGLM3-6B.
* Key Data Points:
* Angles: ~55
* Coordinate plane: ~60
* Spheres: ~70
* Volume of 3d shapes: ~50
* Probability: ~10
* Volume: ~80
### Key Observations
* LLaMA2-7B (Green) consistently underperforms compared to the other three models across almost all problem types.
* Yi-6B (Blue), ChatGLM3-6B (Orange), and DeepSeekMath-7B (Red) show more competitive performance, with varying strengths depending on the problem type.
* There are specific problem types (e.g., Probability) where all models struggle, indicating inherent difficulty in those tasks.
* The accuracy of all models varies significantly depending on the problem type, suggesting that some mathematical concepts are more challenging for these language models than others.
### Interpretation
The chart provides a comparative analysis of the mathematical reasoning abilities of four different language models. The data suggests that:
* Model Architecture Matters: The significant difference in performance between LLaMA2-7B and the other models indicates that architectural choices and training methodologies play a crucial role in mathematical reasoning capabilities.
* Task-Specific Strengths: The varying performance across different problem types highlights that each model has its own strengths and weaknesses. This could be due to the specific training data or the model's ability to generalize to different mathematical concepts.
* Areas for Improvement: The problem types where all models perform poorly identify areas where further research and development are needed to improve the mathematical reasoning abilities of language models.
* DeepSeekMath-7B appears to be the most robust model for math problems, with consistently high accuracy across various problem types.