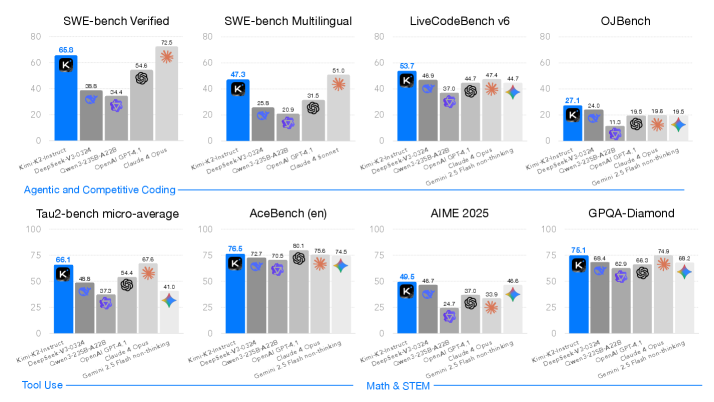
\n
## Bar Charts: Model Performance on Coding Benchmarks
### Overview
The image presents a series of eight bar charts comparing the performance of several large language models (LLMs) across various coding benchmarks. The models evaluated are: Kim-K2-instruct, DeepSeek-V2-024, Open-2.5B-A28, Open-A141, Claude 4 Opus, and Gemini 2.5 flash non-tuning. The benchmarks cover different aspects of coding ability, including verified code, multilingual code, competitive coding, and math/STEM tasks. Each chart displays a score, presumably representing accuracy or some other performance metric, with a "K" symbol marking a key data point.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Lists the LLM models being compared.
* **Y-axis:** Represents the performance score, ranging from 0 to 100. The scale is consistent across all charts.
* **Bars:** Represent the performance of each model on a specific benchmark. The bars are color-coded, with a distinct color for each model.
* **"K" Marker:** A "K" symbol is placed on each bar, indicating a specific score.
* **Titles:** Each chart has a title indicating the benchmark being evaluated.
* **Legend:** The legend is implicit, with each model's color consistently used across all charts.
The charts are arranged in a 2x4 grid. The titles of the charts are:
1. SWE-bench Verified
2. SWE-bench Multilingual
3. LiveCode v6
4. QJBench
5. Tau-2-bench micro-average
6. AceBench (en)
7. AIME 2025
8. GPQA-Diamond
### Detailed Analysis or Content Details
Here's a breakdown of the data extracted from each chart, with approximate values and trend descriptions:
**1. SWE-bench Verified:**
* Kim-K2-instruct: ~65.8
* DeepSeek-V2-024: ~35.4
* Open-2.5B-A28: ~54.6
* Open-A141: ~72.5
* Claude 4 Opus: ~54.6
* Gemini 2.5 flash non-tuning: ~72.5
**2. SWE-bench Multilingual:**
* Kim-K2-instruct: ~47.3
* DeepSeek-V2-024: ~20.9
* Open-2.5B-A28: ~34.6
* Open-A141: ~51.0
* Claude 4 Opus: ~34.6
* Gemini 2.5 flash non-tuning: ~51.0
**3. LiveCode v6:**
* Kim-K2-instruct: ~53.7
* DeepSeek-V2-024: ~37.0
* Open-2.5B-A28: ~44.7
* Open-A141: ~44.7
* Claude 4 Opus: ~44.7
* Gemini 2.5 flash non-tuning: ~44.7
**4. QJBench:**
* Kim-K2-instruct: ~27.1
* DeepSeek-V2-024: ~11.3
* Open-2.5B-A28: ~19.5
* Open-A141: ~19.5
* Claude 4 Opus: ~19.5
* Gemini 2.5 flash non-tuning: ~19.5
**5. Tau-2-bench micro-average:**
* Kim-K2-instruct: ~75.1
* DeepSeek-V2-024: ~57.2
* Open-2.5B-A28: ~66.1
* Open-A141: ~67.6
* Claude 4 Opus: ~67.6
* Gemini 2.5 flash non-tuning: ~67.6
**6. AceBench (en):**
* Kim-K2-instruct: ~76.5
* DeepSeek-V2-024: ~60.1
* Open-2.5B-A28: ~75.6
* Open-A141: ~74.5
* Claude 4 Opus: ~74.5
* Gemini 2.5 flash non-tuning: ~74.5
**7. AIME 2025:**
* Kim-K2-instruct: ~40.5
* DeepSeek-V2-024: ~37.0
* Open-2.5B-A28: ~40.8
* Open-A141: ~40.8
* Claude 4 Opus: ~40.8
* Gemini 2.5 flash non-tuning: ~40.8
**8. GPQA-Diamond:**
* Kim-K2-instruct: ~76.1
* DeepSeek-V2-024: ~66.4
* Open-2.5B-A28: ~66.3
* Open-A141: ~74.6
* Claude 4 Opus: ~74.6
* Gemini 2.5 flash non-tuning: ~74.6
### Key Observations
* **Kim-K2-instruct** consistently performs well, often achieving the highest scores across most benchmarks.
* **DeepSeek-V2-024** generally exhibits the lowest scores across all benchmarks.
* **Open-A141, Claude 4 Opus, and Gemini 2.5 flash non-tuning** often have similar performance levels, clustering together in the higher ranges for several benchmarks.
* The performance differences between models are more pronounced in some benchmarks (e.g., SWE-bench Verified, Tau-2-bench micro-average) than in others (e.g., AIME 2025).
### Interpretation
The data suggests that Kim-K2-instruct is a strong performer across a diverse set of coding benchmarks. DeepSeek-V2-024 appears to lag behind the other models in terms of coding ability, as measured by these benchmarks. The consistent grouping of Open-A141, Claude 4 Opus, and Gemini 2.5 flash non-tuning indicates a similar level of performance for these models.
The variation in performance across benchmarks highlights the importance of evaluating models on a range of tasks to get a comprehensive understanding of their capabilities. Some benchmarks may be more sensitive to specific model architectures or training data. The "K" marker's consistent placement suggests it represents a key performance indicator, potentially a specific test case or a threshold score.
The arrangement of the charts into categories ("Agentic and Competitive Coding", "Tool Use", "Math & STEM") provides a structured view of model performance across different coding domains. This allows for a more nuanced comparison of model strengths and weaknesses. The data suggests that Kim-K2-instruct excels in both coding and math/STEM tasks, while DeepSeek-V2-024 struggles in all areas.