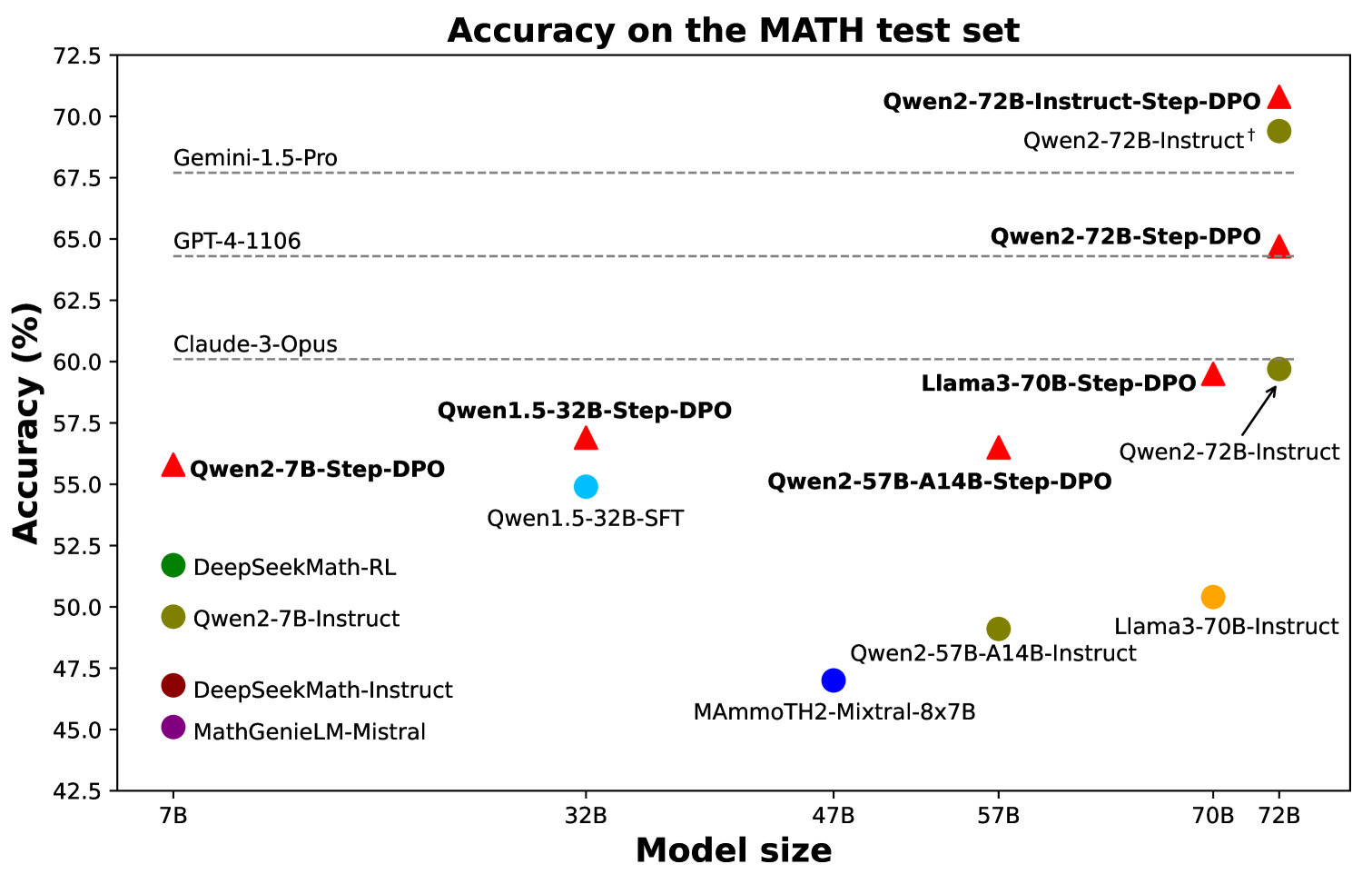
## Scatter Plot: Accuracy on the MATH test set
### Overview
The image is a scatter plot comparing the accuracy of various language models on the MATH test set against their model size. The plot displays model size on the x-axis and accuracy percentage on the y-axis. Each point represents a different model, with its name displayed next to the point. Some models are marked with a red triangle, while others are marked with a green, blue, purple, or orange circle. Horizontal dashed lines indicate the accuracy of some prominent models for reference.
### Components/Axes
* **Title:** Accuracy on the MATH test set
* **X-axis:** Model size, with markers at 7B, 32B, 47B, 57B, 70B, and 72B.
* **Y-axis:** Accuracy (%), with markers from 42.5% to 72.5% in 2.5% increments.
* **Horizontal Dashed Lines (Top to Bottom):**
* Gemini-1.5-Pro (at approximately 67.5% accuracy)
* GPT-4-1106 (at approximately 64.5% accuracy)
* Claude-3-Opus (at approximately 60.5% accuracy)
* **Data Points:** Each point represents a model, with its name displayed next to it. The points are colored differently, but there is no explicit legend provided to explain the color coding.
### Detailed Analysis or Content Details
Here's a breakdown of the models and their approximate positions on the plot:
* **Models with Red Triangle Markers:**
* Qwen2-7B-Step-DPO: Located at approximately (7B, 55.5%)
* Qwen1.5-32B-Step-DPO: Located at approximately (32B, 57.0%)
* Qwen2-57B-A14B-Step-DPO: Located at approximately (57B, 56.0%)
* Llama3-70B-Step-DPO: Located at approximately (70B, 59.5%)
* Qwen2-72B-Step-DPO: Located at approximately (72B, 64.0%)
* Qwen2-72B-Instruct-Step-DPO: Located at approximately (72B, 71.0%)
* **Models with Green Circle Markers:**
* DeepSeekMath-RL: Located at approximately (7B, 52.0%)
* Qwen2-7B-Instruct: Located at approximately (7B, 48.5%)
* Qwen2-72B-Instruct†: Located at approximately (72B, 69.0%)
* **Models with Blue Circle Markers:**
* Qwen1.5-32B-SFT: Located at approximately (32B, 54.0%)
* Qwen2-57B-A14B-Instruct: Located at approximately (57B, 48.5%)
* **Models with Orange Circle Markers:**
* Llama3-70B-Instruct: Located at approximately (70B, 49.5%)
* **Models with Purple Circle Markers:**
* MathGenieLM-Mistral: Located at approximately (7B, 45.0%)
* **Models with Dark Blue Circle Markers:**
* MAmmoTH2-Mixtral-8x7B: Located at approximately (47B, 47.0%)
### Key Observations
* The accuracy generally tends to increase with model size, but there are exceptions.
* Models with "Step-DPO" in their name tend to have higher accuracy than their counterparts without it, especially for larger models like Qwen2-72B.
* The Gemini-1.5-Pro model has the highest accuracy among the models indicated by horizontal lines.
* The Qwen2-72B-Instruct-Step-DPO model achieves the highest accuracy among all models plotted.
* The smallest models (7B) show a wide range of accuracy, suggesting that factors other than size significantly impact performance at this scale.
### Interpretation
The scatter plot illustrates the relationship between model size and accuracy on the MATH test set for various language models. The general trend suggests that larger models tend to perform better, but the specific architecture, training method (e.g., Step-DPO), and other factors play a crucial role in determining the final accuracy. The horizontal lines provide a benchmark against well-known models like Gemini-1.5-Pro and GPT-4-1106. The clustering of points indicates that certain model families (e.g., Qwen, Llama) have different performance characteristics. The presence of outliers suggests that some models are either particularly effective or ineffective for their size. The plot highlights the importance of both model size and training techniques in achieving high accuracy on complex tasks like the MATH test set.