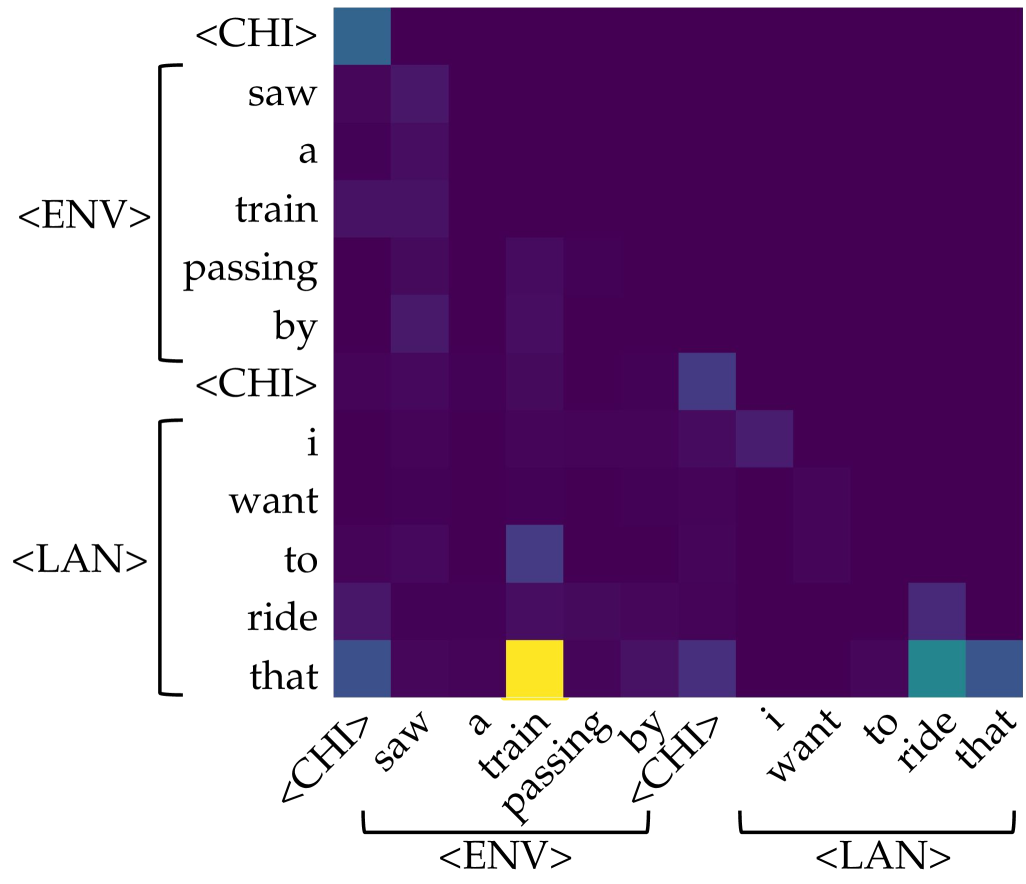
\n
## Heatmap/Attention Matrix: Token-to-Token Attention Weights
### Overview
The image displays a square heatmap, likely representing an attention matrix from a neural network model (e.g., a Transformer). It visualizes the strength of association or "attention" between tokens in a sequence. The sequence appears to be a sentence or utterance split into two conceptual parts: an environmental description (`<ENV>`) and a language-based desire (`<LAN>`), delimited by special tokens `<CHI>`.
### Components/Axes
* **Type:** Heatmap / Attention Matrix.
* **Axes:** Both the vertical (Y) and horizontal (X) axes represent the same sequence of tokens. The labels are identical and ordered from top to bottom (Y-axis) and left to right (X-axis).
* **Token Sequence:** The sequence is: `<CHI>`, `saw`, `a`, `train`, `passing`, `by`, `<CHI>`, `i`, `want`, `to`, `ride`, `that`.
* **Groupings:**
* **Vertical Axis (Left):** Tokens are grouped by brackets. The first group, labeled `<ENV>`, contains `saw`, `a`, `train`, `passing`, `by`. The second group, labeled `<LAN>`, contains `i`, `want`, `to`, `ride`, `that`. The `<CHI>` tokens act as separators.
* **Horizontal Axis (Bottom):** The same grouping is indicated by brackets below the axis labels. The first bracket groups `saw` through `by` under `<ENV>`. The second bracket groups `i` through `that` under `<LAN>`. The `<CHI>` tokens are not within these brackets.
* **Color Scale (Implied Legend):** There is no explicit legend. The color gradient represents the magnitude of the attention weight.
* **Dark Purple/Black:** Represents very low or near-zero attention weight.
* **Teal/Blue-Green:** Represents a moderate attention weight.
* **Bright Yellow:** Represents the highest attention weight in the matrix.
* **Spatial Layout:** The matrix is a perfect square. The axis labels are rotated 45 degrees on the horizontal axis for readability. The grouping brackets and labels (`<ENV>`, `<LAN>`) are positioned to the left of the Y-axis and below the X-axis.
### Detailed Analysis
The heatmap shows a sparse attention pattern, with most cells being dark purple (low weight). Significant activations (brighter colors) are concentrated in specific cells.
**Trend Verification:** The overall trend is that most tokens attend weakly to most other tokens. Attention is not uniformly distributed but is focused on a few key relationships.
**Key Data Points (Approximate, based on color intensity):**
1. **Strongest Activation (Bright Yellow):** The cell at the intersection of the row for token `that` (Y-axis, within `<LAN>`) and the column for token `train` (X-axis, within `<ENV>`). This indicates the token "that" is paying very strong attention to the token "train".
2. **Moderate Activations (Teal/Blue):**
* Row `that` (Y) / Column `ride` (X): Moderate attention.
* Row `that` (Y) / Column `<CHI>` (first instance, X): Moderate attention.
* Row `<CHI>` (first instance, Y) / Column `saw` (X): Moderate attention.
* Row `to` (Y) / Column `train` (X): Moderate attention.
* Row `i` (Y) / Column `<CHI>` (second instance, X): Moderate attention.
* Row `want` (Y) / Column `<CHI>` (second instance, X): Moderate attention.
3. **Notable Pattern:** The token `that` (the final token) shows the most diverse and strongest attention profile, looking back at both the environmental object (`train`) and its action (`ride`), as well as the delimiter `<CHI>`.
4. **Diagonal:** The main diagonal (where a token attends to itself) does not show uniformly high values, which is atypical for some attention visualizations but common in others (e.g., when visualizing attention from a later token to earlier ones).
### Key Observations
* **Sparse Attention:** The model's attention is highly selective, not diffuse.
* **Cross-Phrase Attention:** The strongest link (`that` -> `train`) connects a pronoun in the `<LAN>` phrase to a noun in the `<ENV>` phrase, suggesting the model is resolving coreference ("that" refers to "train").
* **Delimiter Role:** The `<CHI>` tokens receive moderate attention from several words, indicating they may serve as important structural anchors in the sequence.
* **Asymmetry:** The attention pattern is not symmetric. For example, the attention from `train` to `that` (row `train`, column `that`) is very weak (dark purple), while the reverse is the strongest in the matrix.
### Interpretation
This heatmap likely visualizes the self-attention mechanism of a Transformer-based model processing a multimodal or structured input. The sequence combines an observed event ("saw a train passing by") with a desired action ("i want to ride that").
**What the data suggests:**
1. **Coreference Resolution:** The model has successfully learned that the word "that" in the desire phrase refers to the "train" mentioned earlier. This is the primary and strongest relationship captured.
2. **Contextual Binding:** The model attends from action verbs (`ride`) and pronouns (`that`) back to the relevant environmental object (`train`), demonstrating an understanding of the semantic relationship between the two phrases.
3. **Structural Awareness:** Attention to the `<CHI>` tokens suggests the model uses these special symbols to segment the input into meaningful chunks (observation vs. desire), and these segments influence each other.
**Why it matters:** This visualization provides interpretability into the model's "reasoning" process. It shows the model isn't just processing tokens in isolation but is actively building connections between concepts across different parts of the input to form a coherent understanding. The strong `that`->`train` link is evidence of successful grounding, where a linguistic reference is connected to its antecedent in the context.
**Anomaly/Note:** The lack of strong self-attention on the diagonal is a design choice of the specific attention head or visualization method. It emphasizes inter-token relationships over intra-token ones.