\n
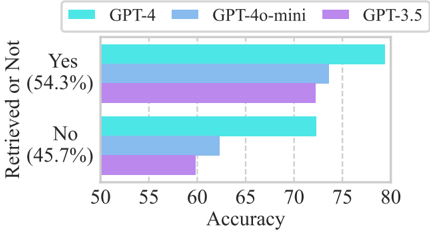
## Bar Chart: Retrieval Accuracy Comparison of GPT Models
### Overview
This is a horizontal bar chart comparing the accuracy of three GPT models (GPT-4, GPT-4o-mini, and GPT-3.5) based on whether information was retrieved ("Yes" or "No"). The chart displays accuracy on the x-axis and retrieval status on the y-axis.
### Components/Axes
* **X-axis:** "Accuracy" ranging from 50 to 80, with tick marks at 55, 60, 65, 70, 75.
* **Y-axis:** "Retrieved or Not" with two categories: "Yes" and "No".
* **Legend:** Located at the top-left corner, with the following entries:
* GPT-4 (Cyan)
* GPT-4o-mini (Light Blue)
* GPT-3.5 (Lavender/Purple)
* **Data Labels:** Percentage values are displayed next to the "Yes" category bars: (54.3%).
### Detailed Analysis
The chart presents accuracy data for each model under two conditions: "Yes" (information retrieved) and "No" (information not retrieved).
**GPT-4 (Cyan):**
* **Yes:** The bar extends from approximately 72 to 79 on the accuracy scale. Estimated accuracy: 78.5 ± 1.5.
* **No:** The bar extends from approximately 69 to 72 on the accuracy scale. Estimated accuracy: 70.5 ± 1.5.
**GPT-4o-mini (Light Blue):**
* **Yes:** The bar extends from approximately 67 to 74 on the accuracy scale. Estimated accuracy: 70.5 ± 1.5.
* **No:** The bar extends from approximately 60 to 64 on the accuracy scale. Estimated accuracy: 62.0 ± 1.5.
**GPT-3.5 (Lavender/Purple):**
* **Yes:** The bar extends from approximately 67 to 73 on the accuracy scale. Estimated accuracy: 70.0 ± 1.5.
* **No:** The bar extends from approximately 57 to 61 on the accuracy scale. Estimated accuracy: 59.0 ± 1.5.
### Key Observations
* GPT-4 consistently demonstrates the highest accuracy in both "Yes" and "No" retrieval scenarios.
* GPT-4o-mini and GPT-3.5 exhibit similar accuracy levels, with GPT-4o-mini slightly outperforming GPT-3.5 in both scenarios.
* Accuracy is generally higher when information is retrieved ("Yes") compared to when it is not ("No") for all models.
* The overall accuracy difference between the models is more pronounced in the "Yes" scenario.
### Interpretation
The data suggests that GPT-4 is the most accurate model for information retrieval, regardless of whether the information is successfully retrieved or not. GPT-4o-mini offers a performance level between GPT-4 and GPT-3.5. The difference in accuracy between the "Yes" and "No" scenarios indicates that the models are more reliable when information is successfully retrieved, which is expected. The chart highlights the trade-offs between model size/complexity (GPT-4 being the largest) and accuracy. The percentage value (54.3%) next to the "Yes" category bars likely represents the overall proportion of times information was retrieved across all models, providing context for the accuracy scores. This suggests that approximately 54.3% of the time, the models were able to retrieve the requested information. The data implies that the models are more accurate when they *can* find the information, but still have limitations when they cannot.