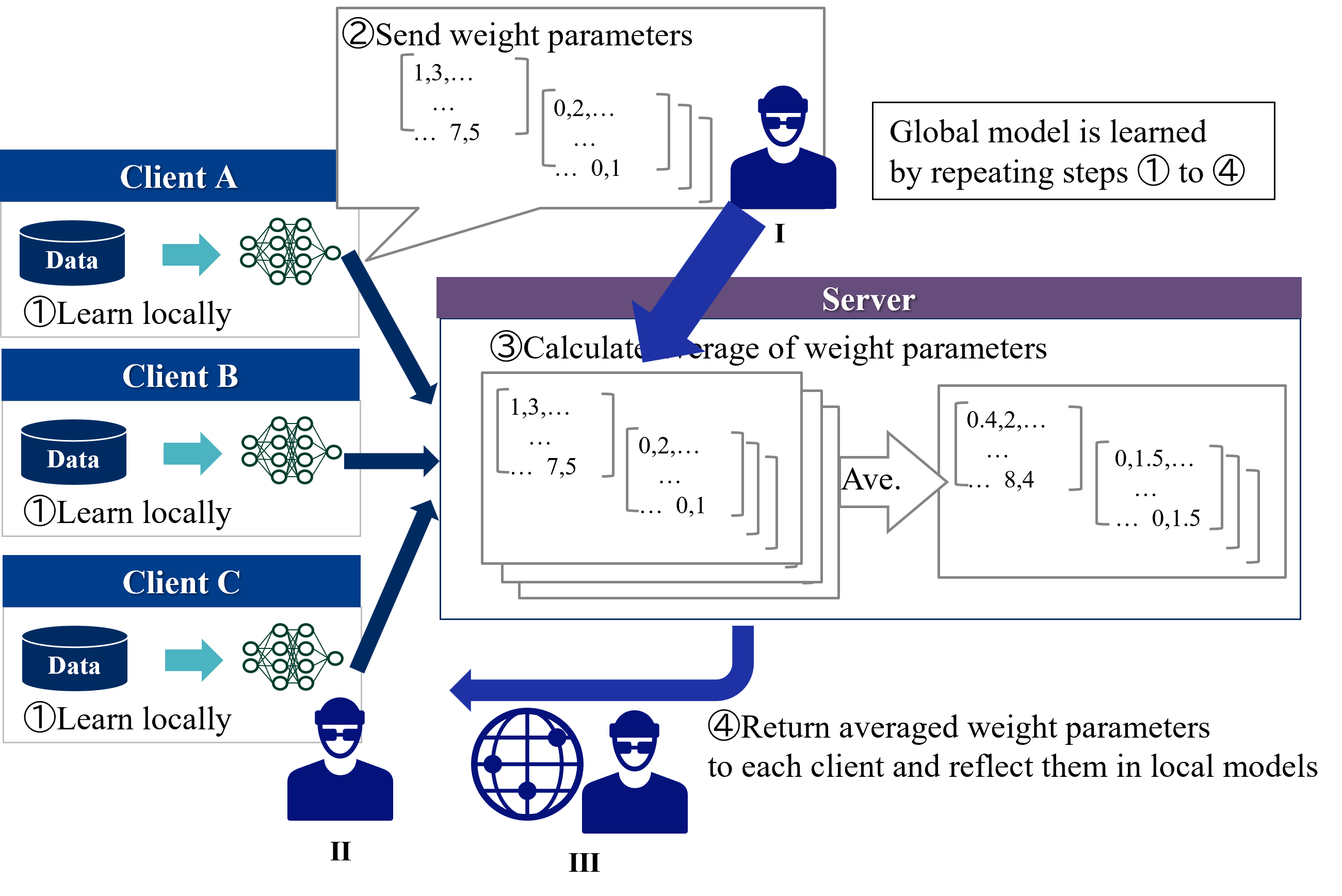
## Flowchart: Federated Learning Process
### Overview
The diagram illustrates a federated learning workflow where multiple clients (A, B, C) collaboratively train a global machine learning model while keeping their raw data decentralized. The process involves four iterative steps: local training, parameter aggregation, and model updating.
### Components/Axes
1. **Clients (A, B, C)**:
- Each client has:
- A "Data" container (blue cylinder)
- A neural network symbol (green circles)
- A "Learn locally" label (①)
2. **Server**:
- Central processing unit with:
- "Send weight parameters" (②)
- "Calculate average of weight parameters" (③)
- "Return averaged weight parameters" (④)
3. **Flow Indicators**:
- Blue arrows showing data/parameter movement
- Speech bubbles with example numerical values
- Global model learning statement
### Detailed Analysis
1. **Local Training Phase**:
- Each client independently trains a model on its local data
- Example parameters shown in speech bubble:
- Client A: [1,3,7.5], [0.2,0.1]
- Client B: [1,3,7.5], [0.2,0.1]
- Client C: [1,3,7.5], [0.2,0.1]
2. **Parameter Aggregation**:
- Server receives parameters from all clients
- Calculates average weights:
- First parameter: (1+1+1)/3 = 1.0
- Second parameter: (3+3+3)/3 = 3.0
- Third parameter: (7.5+7.5+7.5)/3 = 7.5
- Fourth parameter: (0.2+0.2+0.2)/3 = 0.2
- Fifth parameter: (0.1+0.1+0.1)/3 = 0.1
3. **Model Update**:
- Averaged parameters (1.0, 3.0, 7.5, 0.2, 0.1) are sent back to clients
- Clients update their local models with these global parameters
### Key Observations
- All clients show identical parameter values in the example, suggesting homogeneous training conditions
- The server acts as a neutral aggregator without access to raw data
- The process is explicitly iterative ("repeating steps ① to ④")
- Numerical examples use simple arithmetic for clarity
### Interpretation
This diagram demonstrates a privacy-preserving machine learning paradigm where:
1. **Data Localization**: Raw data never leaves client devices, addressing privacy concerns
2. **Collaborative Intelligence**: Decentralized data sources contribute to a shared model
3. **Iterative Improvement**: Continuous parameter updates refine the global model
4. **Simplified Aggregation**: The example uses arithmetic mean, though real implementations might use more sophisticated methods (e.g., federated averaging)
The workflow emphasizes trust minimization between clients and the server, making it suitable for healthcare, finance, and IoT applications where data sovereignty is critical. The numerical examples, while simplified, illustrate the core concept of parameter averaging across distributed systems.