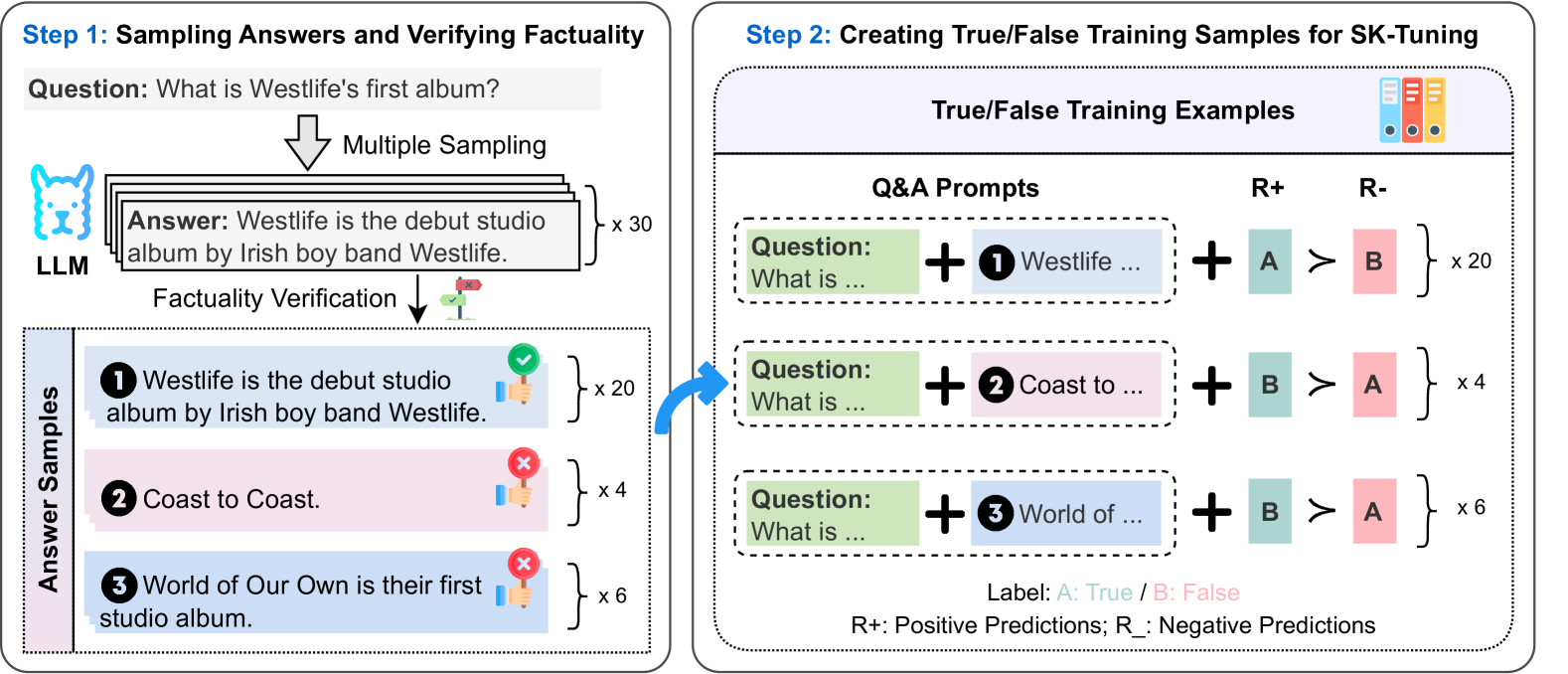
# Technical Document Extraction: SK-Tuning Training Pipeline
This document describes a two-step technical process for sampling answers, verifying factuality, and creating training samples for "SK-Tuning." The image is a flow diagram divided into two primary modules.
---
## Step 1: Sampling Answers and Verifying Factuality
This module describes the initial data generation and labeling phase.
### 1.1 Input and Generation
* **Question:** "What is Westlife's first album?"
* **Process:** The question is fed into an **LLM** (represented by a blue llama icon).
* **Action:** **Multiple Sampling** is performed.
* **Output:** A stack of answer cards labeled **"x 30"**, indicating 30 samples were generated.
* **Sample Text:** "Answer: Westlife is the debut studio album by Irish boy band Westlife."
### 1.2 Factuality Verification
The generated answers undergo a **Factuality Verification** process (represented by a signpost icon with a green check and red 'x'). This results in three categorized **Answer Samples**:
| ID | Answer Text | Factuality Status | Quantity |
| :--- | :--- | :--- | :--- |
| **1** | "Westlife is the debut studio album by Irish boy band Westlife." | **True** (Green checkmark/Blue background) | x 20 |
| **2** | "Coast to Coast." | **False** (Red 'x'/Pink background) | x 4 |
| **3** | "World of Our Own is their first studio album." | **False** (Red 'x'/Pink background) | x 6 |
---
## Step 2: Creating True/False Training Samples for SK-Tuning
This module describes how the verified samples from Step 1 are converted into preference-based training examples.
### 2.1 Component Definitions
* **Q&A Prompts:** Combinations of the original question and the sampled answers.
* **R+ (Positive Predictions):** Represented by a teal box labeled **A**.
* **R- (Negative Predictions):** Represented by a pink box labeled **B**.
* **Preference Operator:** The symbol **$\succ$** (greater than/preferred to) is used to show the relationship between R+ and R-.
* **Legend:**
* **Label:** A: True / B: False
* **R+:** Positive Predictions
* **R-:** Negative Predictions
### 2.2 Training Example Construction
The system creates pairs where a "True" label is preferred over a "False" label.
| Prompt Composition | Preference Logic | Quantity |
| :--- | :--- | :--- |
| **Question** + **Answer 1** (True) | **A** (True) $\succ$ **B** (False) | x 20 |
| **Question** + **Answer 2** (False) | **B** (False) $\succ$ **A** (True) | x 4 |
| **Question** + **Answer 3** (False) | **B** (False) $\succ$ **A** (True) | x 6 |
**Note on Logic:**
* For the correct answer (1), the model is trained to predict "True" (A) over "False" (B).
* For the incorrect answers (2 and 3), the model is trained to predict "False" (B) over "True" (A).
---
## Summary of Flow
1. **Generation:** An LLM generates 30 responses to a specific factual question.
2. **Labeling:** Responses are manually or automatically verified. In this case, 20 are correct and 10 are incorrect (split 4/6).
3. **Formatting:** These are formatted into "Q&A Prompts."
4. **Optimization:** The prompts are used to create 30 training examples for SK-Tuning, where the objective is to rank the correct factuality label (True for correct statements, False for incorrect statements) higher than the incorrect label.