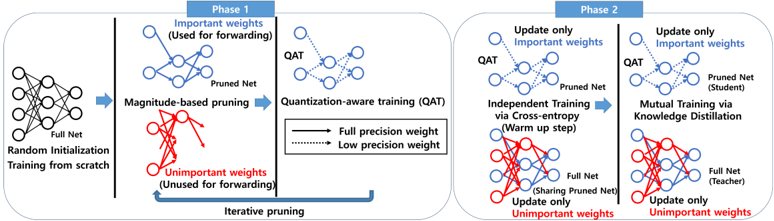
## Diagram: Two-Phase Neural Network Pruning and Training Process
### Overview
The image is a technical flowchart illustrating a two-phase methodology for training a neural network with pruning and quantization. The process begins with a full network trained from scratch and proceeds through iterative pruning (Phase 1) followed by two alternative training strategies (Phase 2). The diagram uses color-coding (blue for "Important weights," red for "Unimportant weights") and line styles (solid for "Full precision weight," dotted for "Low precision weight") to distinguish components.
### Components/Axes
The diagram is divided into two main panels, labeled **Phase 1** and **Phase 2**, connected by a large arrow indicating sequential flow.
**Phase 1: Pruning and Quantization-Aware Training (QAT)**
* **Initial State:** A "Full Net" with "Random Initialization" and "Training from scratch."
* **Process:** "Magnitude-based pruning" separates weights into two groups:
* **Important weights (Used for forwarding):** Shown in blue. These form the "Pruned Net."
* **Unimportant weights (Unused for forwarding):** Shown in red.
* **Legend (Center):** Defines the visual language:
* Solid line: "Full precision weight"
* Dotted line: "Low precision weight"
* **Next Step:** The "Pruned Net" undergoes "Quantization-aware training (QAT)."
* **Feedback Loop:** An arrow labeled "Iterative pruning" loops back from the QAT step to the magnitude-based pruning step, indicating this process repeats.
**Phase 2: Training Strategies**
This phase presents two parallel training paths, both starting from the QAT model produced in Phase 1.
* **Left Path: Independent Training via Cross-entropy (Warm up step)**
* **Action:** "Update only Important weights" (blue lines) in the "Pruned Net (Student)."
* **Action:** "Update only Unimportant weights" (red lines) in the "Full Net."
* **Note:** The Full Net is shown "Sharing Pruned Net" for its important weights.
* **Right Path: Mutual Training via Knowledge Distillation**
* **Action:** "Update only Important weights" (blue lines) in the "Pruned Net (Student)."
* **Action:** "Update only Unimportant weights" (red lines) in the "Full Net (Teacher)."
* **Note:** The Full Net (Teacher) provides guidance to the Student.
### Detailed Analysis
The diagram details a structured pipeline for creating efficient neural networks.
**Phase 1 Flow:**
1. A full-sized network is initialized and trained.
2. Weights are pruned based on magnitude, creating a sparse "Pruned Net" containing only the "Important weights" (blue).
3. The Pruned Net undergoes Quantization-Aware Training (QAT), which simulates the effects of low-precision (quantized) inference during training, preparing the model for deployment.
4. The "Iterative pruning" loop suggests steps 2 and 3 are repeated, progressively refining the pruned and quantized model.
**Phase 2 Flow (Two Alternatives):**
* **Independent Training:** The pruned student network is fine-tuned using a standard cross-entropy loss. Concurrently, the unimportant weights (red) in the original full network are also updated, but they remain unused for forwarding. This appears to be a warm-up or preparatory stage.
* **Mutual Training:** This is a more advanced stage employing knowledge distillation. The full network acts as a "Teacher," and the pruned network is the "Student." The Student's important weights are updated to mimic the Teacher's behavior, while the Teacher's own unimportant weights are also updated. This suggests a co-adaptation or mutual refinement process.
### Key Observations
1. **Weight Role Separation:** The core concept is the strict separation of weights into "Important" (blue, used for inference) and "Unimportant" (red, unused for inference but potentially updated during training).
2. **Precision Differentiation:** The legend explicitly distinguishes between full-precision and low-precision weights, highlighting that quantization is a key part of the pipeline.
3. **Iterative Refinement:** Phase 1 is not a single pass but an iterative loop, suggesting the pruning and QAT process is repeated to achieve an optimal sparse, quantized model.
4. **Two-Stage Training:** Phase 2 is not a single method but presents a progression from a simpler "Independent Training" warm-up to a more complex "Mutual Training" distillation scheme.
5. **Spatial Layout:** The legend is centrally placed between the two phases for easy reference. Phase 1 flows left-to-right, while Phase 2 presents two side-by-side alternatives.
### Interpretation
This diagram outlines a sophisticated methodology for **model compression and efficient training**. The process aims to produce a neural network that is both **sparse** (pruned) and **quantized** (low-precision), which drastically reduces its memory footprint and computational cost for deployment.
* **Phase 1** focuses on **structural efficiency**: identifying and retaining only the most critical connections (pruning) and adapting the model to operate with lower numerical precision (QAT). The iterative nature implies that finding the optimal sparse structure is an ongoing search.
* **Phase 2** focuses on **performance recovery and enhancement**: After aggressive pruning and quantization, model accuracy typically drops. The two strategies shown are methods to recover that accuracy. The "Independent Training" warms up the model, while "Mutual Training via Knowledge Distillation" uses the original, larger network as a teacher to guide the compressed student network, potentially recovering performance lost during compression.
The overall narrative is one of **creating a lightweight, efficient model without sacrificing excessive accuracy**, by carefully managing which weights are used, at what precision, and how they are trained in relation to a larger teacher model. The separation of "important" and "unimportant" weights throughout the process is the central, defining principle.