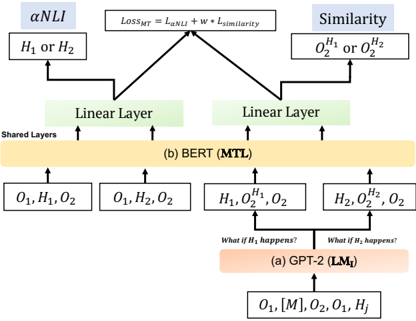
## Diagram: Machine Learning Model Architecture Comparison (GPT-2 vs BERT with Custom Components)
### Overview
The diagram illustrates a hybrid machine learning architecture combining elements of GPT-2 (LM₁) and BERT (MTL) models, with additional components for αNLI (Adversarial Natural Language Inference), similarity scoring, and multi-task learning (MTL). The architecture includes shared layers, linear layers, hypothesis-specific outputs, and a composite loss function.
### Components/Axes
1. **Core Components**:
- **Shared Layers**: Central processing unit for both GPT-2 and BERT variants
- **Linear Layers**: Two separate linear transformation modules (one per model variant)
- **αNLI**: Adversarial Natural Language Inference component
- **Similarity**: Similarity scoring mechanism
- **Loss_MT**: Composite loss function (L_αNLI + w * L_similarity)
2. **Input/Output Flows**:
- **Inputs**: O₁, H₁, O₂ (base outputs)
- **Hypothesis Variants**: H₁ or H₂ (conditional processing paths)
- **Output Variants**:
- GPT-2 (LM₁): O₁, [M], O₂, O₁, H_j
- BERT (MTL): H₁, O₂¹, O₂; H₂, O₂², O₂
3. **Key Elements**:
- **Conditional Processing**: "What if H₁ happens?" and "What if H₂ happens?" decision nodes
- **Output Modifiers**: O₂¹/O₂² (hypothesis-specific output versions)
- **Loss Function**: Weighted combination of αNLI loss and similarity loss
### Detailed Analysis
1. **Shared Layers**:
- Process base inputs (O₁, H₁, O₂) for both model variants
- Serve as foundation for both GPT-2 and BERT implementations
2. **Linear Layers**:
- Two distinct linear transformation modules
- One for GPT-2 (LM₁) path
- One for BERT (MTL) path
3. **αNLI Component**:
- Takes H₁ or H₂ as input
- Feeds into Loss_MT calculation
4. **Similarity Scoring**:
- Processes O₂¹ or O₂²
- Contributes to Loss_MT via weighted term (w * L_similarity)
5. **Hypothesis-Specific Paths**:
- **H₁ Path**:
- Input: H₁
- Output: O₂¹, O₂
- **H₂ Path**:
- Input: H₂
- Output: O₂², O₂
6. **Output Variants**:
- **GPT-2 (LM₁)**: Maintains original output structure with additional hypothesis component (H_j)
- **BERT (MTL)**: Produces hypothesis-specific output versions (O₂¹/O₂²) while maintaining base output (O₂)
### Key Observations
1. **Architectural Integration**:
- Shared layers enable parameter efficiency
- Linear layers provide model-specific adaptations
2. **Multi-Task Capabilities**:
- αNLI component adds adversarial training dimension
- Similarity scoring enables cross-output consistency
3. **Conditional Processing**:
- Model behavior adapts based on hypothesis (H₁/H₂)
- Different output configurations for each hypothesis path
4. **Loss Function Design**:
- Balances adversarial training (L_αNLI) with output consistency (L_similarity)
- Weight parameter (w) controls similarity loss contribution
### Interpretation
This architecture demonstrates a sophisticated approach to multi-task learning in NLP:
1. **Efficiency Through Sharing**: Shared layers reduce parameter count while maintaining model flexibility
2. **Adversarial Robustness**: αNLI component suggests focus on handling challenging linguistic cases
3. **Hypothesis-Aware Processing**: The model can adapt its output based on different linguistic hypotheses
4. **Composite Training Objective**: The loss function balances multiple objectives, suggesting a focus on both adversarial performance and output consistency
The diagram reveals a hybrid approach that combines the strengths of transformer-based models (GPT-2's generative capabilities and BERT's bidirectional understanding) with custom components for specific NLP tasks. The conditional processing paths indicate the model's ability to handle different linguistic scenarios, while the shared architecture components suggest efficient parameter utilization.