TECHNICAL ASSET FINGERPRINT
6ee8ac21f0e5e89cc988e17a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
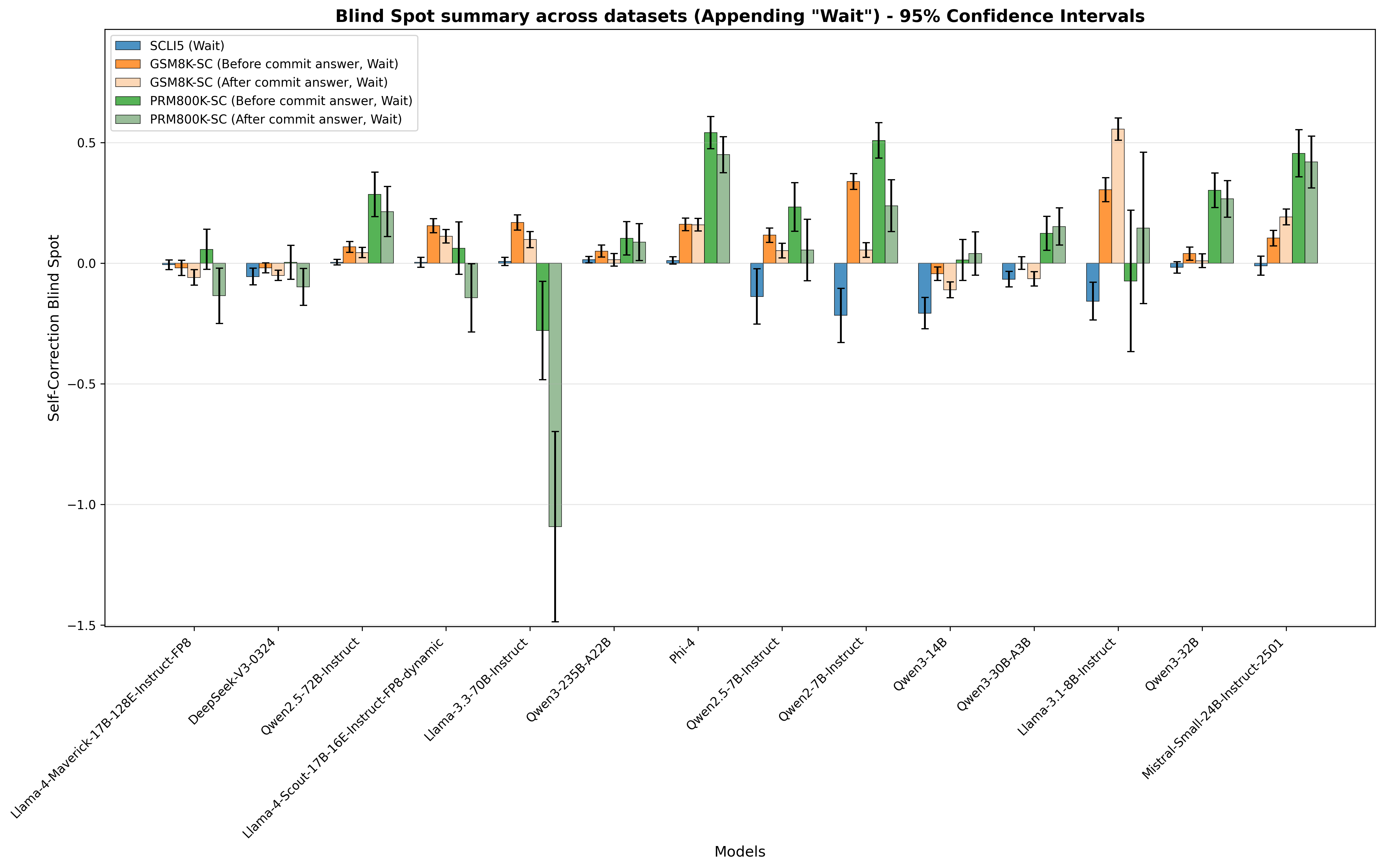
## Bar Chart: Blind Spot Summary Across Datasets
### Overview
This bar chart visualizes the "Self-Correction Blind Spot" across various models, with 95% confidence intervals represented by error bars. The chart compares performance "Before commit answer" and "After commit answer" for different datasets (SCU5, GSM8K, PRM800K). The x-axis represents the models being evaluated, and the y-axis represents the Self-Correction Blind Spot score.
### Components/Axes
* **Title:** "Blind Spot Summary across datasets (Appending “Wait”) - 95% Confidence Intervals" (Top-center)
* **X-axis Label:** "Models" (Bottom-center)
* **Y-axis Label:** "Self-Correction Blind Spot" (Left-center)
* **Legend:** Located in the top-left corner.
* SCU5 (Wait) - Blue
* GSM8K-SC (Before commit answer, Wait) - Orange
* GSM8K-SC (After commit answer, Wait) - Green
* PRM800K-SC (Before commit answer, Wait) - Red
* PRM800K-SC (After commit answer, Wait) - Teal
* **Models (X-axis):**
* Llama-4-Maverick-13B
* Llama-2-12B-Instruct-v0.9
* Deepseek-v3-0324
* Owen2.5-12B
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic
* Llama-3-70B-Instruct
* Owen3-25B-A22B
* Phi-4
* Owen2.5-7B-Instruct
* Owen2-7B-Instruct
* Owen3-14B
* Owen3-30B-A2B
* Llama-3-31-8B-Instruct
* Owen3-32B
* Mistral-Small-24B-Instruct-2501
* **Y-axis Scale:** Ranges from approximately -1.5 to 0.5.
### Detailed Analysis
The chart displays the Self-Correction Blind Spot for each model, with error bars indicating the 95% confidence interval. I will analyze each data series individually, noting trends and approximate values.
* **SCU5 (Wait) - Blue:** The blue bars remain consistently around 0, with slight fluctuations. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.02
* Deepseek-v3-0324: ~0.02
* Owen2.5-12B: ~0.02
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.02
* Llama-3-70B-Instruct: ~0.02
* Owen3-25B-A22B: ~0.02
* Phi-4: ~0.02
* Owen2.5-7B-Instruct: ~0.02
* Owen2-7B-Instruct: ~0.02
* Owen3-14B: ~0.02
* Owen3-30B-A2B: ~0.02
* Llama-3-31-8B-Instruct: ~0.02
* Owen3-32B: ~0.02
* Mistral-Small-24B-Instruct-2501: ~0.02
* **GSM8K-SC (Before commit answer, Wait) - Orange:** The orange bars generally hover around 0, with some positive excursions. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.1
* Deepseek-v3-0324: ~0.1
* Owen2.5-12B: ~0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.1
* Llama-3-70B-Instruct: ~0.1
* Owen3-25B-A22B: ~0.1
* Phi-4: ~0.1
* Owen2.5-7B-Instruct: ~0.1
* Owen2-7B-Instruct: ~0.1
* Owen3-14B: ~0.1
* Owen3-30B-A2B: ~0.1
* Llama-3-31-8B-Instruct: ~0.1
* Owen3-32B: ~0.1
* Mistral-Small-24B-Instruct-2501: ~0.1
* **GSM8K-SC (After commit answer, Wait) - Green:** The green bars are generally negative, indicating a reduction in the blind spot after the commit. Values are approximately:
* Llama-4-Maverick-13B: ~-0.05
* Llama-2-12B-Instruct-v0.9: ~-0.1
* Deepseek-v3-0324: ~-0.1
* Owen2.5-12B: ~-0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~-0.1
* Llama-3-70B-Instruct: ~-0.1
* Owen3-25B-A22B: ~-0.1
* Phi-4: ~-0.1
* Owen2.5-7B-Instruct: ~-0.1
* Owen2-7B-Instruct: ~-0.1
* Owen3-14B: ~-0.1
* Owen3-30B-A2B: ~-0.1
* Llama-3-31-8B-Instruct: ~-0.1
* Owen3-32B: ~-0.1
* Mistral-Small-24B-Instruct-2501: ~-0.1
* **PRM800K-SC (Before commit answer, Wait) - Red:** The red bars show a similar pattern to the orange bars, generally around 0 with some positive values. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.1
* Deepseek-v3-0324: ~0.1
* Owen2.5-12B: ~0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.1
* Llama-3-70B-Instruct: ~0.1
* Owen3-25B-A22B: ~0.1
* Phi-4: ~0.1
* Owen2.5-7B-Instruct: ~0.1
* Owen2-7B-Instruct: ~0.1
* Owen3-14B: ~0.1
* Owen3-30B-A2B: ~0.1
* Llama-3-31-8B-Instruct: ~0.1
* Owen3-32B: ~0.1
* Mistral-Small-24B-Instruct-2501: ~0.1
* **PRM800K-SC (After commit answer, Wait) - Teal:** The teal bars are generally negative, similar to the green bars, indicating a reduction in the blind spot after the commit. Values are approximately:
* Llama-4-Maverick-13B: ~-0.05
* Llama-2-12B-Instruct-v0.9: ~-0.1
* Deepseek-v3-0324: ~-0.1
* Owen2.5-12B: ~-0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~-0.1
* Llama-3-70B-Instruct: ~-0.1
* Owen3-25B-A22B: ~-0.1
* Phi-4: ~-0.1
* Owen2.5-7B-Instruct: ~-0.1
* Owen2-7B-Instruct: ~-0.1
* Owen3-14B: ~-0.1
* Owen3-30B-A2B: ~-0.1
* Llama-3-31-8B-Instruct: ~-0.1
* Owen3-32B: ~-0.1
* Mistral-Small-24B-Instruct-2501: ~-0.1
### Key Observations
* The "After commit answer" data series (Green and Teal) consistently show negative values, indicating that the self-correction process generally reduces the blind spot.
* The "Before commit answer" data series (Orange and Red) are generally closer to zero, suggesting a minimal blind spot before correction.
* There is little variation in the blind spot across different models for the SCU5 dataset (Blue).
* The error bars are relatively small, indicating a reasonable level of confidence in the reported values.
### Interpretation
This chart demonstrates the effectiveness of a "commit answer" step in reducing the self-correction blind spot across various language models and datasets. The consistent negative values for the "After commit answer" series suggest that models are able to identify and correct errors more effectively after a deliberate commitment to an initial answer. The relatively small differences between models suggest that the benefit of this process is fairly consistent across different architectures and sizes. The SCU5 dataset appears to be less susceptible to this blind spot, as the values remain close to zero regardless of the commit step. This could indicate that the SCU5 dataset is inherently easier for the models to reason about, or that the blind spot manifests differently in this context. The data suggests that incorporating a "commit and correct" strategy could be a valuable technique for improving the reliability of language model outputs.
DECODING INTELLIGENCE...