\n
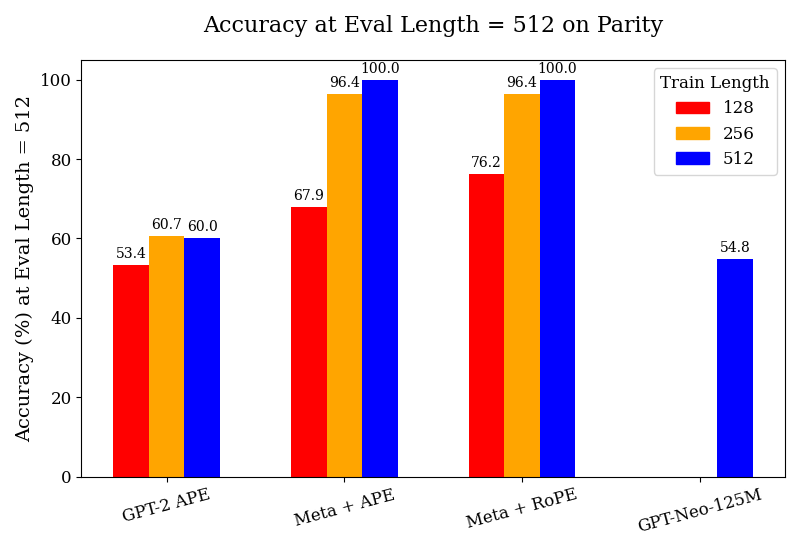
## Grouped Bar Chart: Accuracy at Eval Length = 512 on Parity
### Overview
This is a grouped bar chart comparing the accuracy (in percentage) of four different language model configurations when evaluated on a sequence length of 512 tokens. The performance is measured across three different training sequence lengths (128, 256, and 512 tokens). The chart demonstrates how model architecture and training length affect evaluation accuracy on a "Parity" task.
### Components/Axes
* **Chart Title:** "Accuracy at Eval Length = 512 on Parity"
* **Y-Axis:**
* **Label:** "Accuracy (%) at Eval Length = 512"
* **Scale:** Linear scale from 0 to 100, with major tick marks at intervals of 20 (0, 20, 40, 60, 80, 100).
* **X-Axis:**
* **Categories (Model Configurations):** Four distinct groups are labeled from left to right:
1. "GPT-2 APE"
2. "Meta + APE"
3. "Meta + RoPE"
4. "GPT-Neo-125M"
* **Legend:**
* **Title:** "Train Length"
* **Placement:** Top-right corner of the chart area.
* **Items:**
* Red square: "128"
* Orange square: "256"
* Blue square: "512"
* **Data Series:** Three bars per model group (except the last), colored according to the legend. Each bar has its exact numerical value annotated above it.
### Detailed Analysis
The chart presents the following data points for each model configuration and training length:
1. **GPT-2 APE:**
* Train Length 128 (Red): **53.4%**
* Train Length 256 (Orange): **60.7%**
* Train Length 512 (Blue): **60.0%**
* *Trend:* Accuracy increases from train length 128 to 256, then plateaus or slightly decreases at 512.
2. **Meta + APE:**
* Train Length 128 (Red): **67.9%**
* Train Length 256 (Orange): **96.4%**
* Train Length 512 (Blue): **100.0%**
* *Trend:* A strong, consistent upward trend. Accuracy improves dramatically with longer training, reaching perfect accuracy at train length 512.
3. **Meta + RoPE:**
* Train Length 128 (Red): **76.2%**
* Train Length 256 (Orange): **96.4%**
* Train Length 512 (Blue): **100.0%**
* *Trend:* Similar strong upward trend as "Meta + APE". It starts at a higher baseline (76.2% vs 67.9%) for train length 128 and also reaches perfect accuracy at train length 512.
4. **GPT-Neo-125M:**
* Train Length 128 (Red): **No bar present.**
* Train Length 256 (Orange): **No bar present.**
* Train Length 512 (Blue): **54.8%**
* *Trend:* Only data for train length 512 is provided. Its performance (54.8%) is comparable to the lowest-performing configuration (GPT-2 APE at train length 128).
### Key Observations
* **Performance Ceiling:** Both "Meta" configurations (with APE and RoPE) achieve **100.0% accuracy** when trained on sequences of length 512.
* **Training Length Impact:** For the "Meta" models, increasing the training sequence length from 128 to 512 tokens yields a massive performance gain of over 30 percentage points.
* **Model Comparison:** The "Meta" architectures significantly outperform the baseline GPT-2 and GPT-Neo models on this task, especially with longer training.
* **Missing Data:** The GPT-Neo-125M model only has a result for the longest training length (512), suggesting it may not have been evaluated or trained on shorter sequences for this experiment.
* **APE vs. RoPE:** At the shortest training length (128), "Meta + RoPE" (76.2%) shows a clear advantage over "Meta + APE" (67.9%). This gap closes at longer training lengths where both reach the same high accuracy.
### Interpretation
This chart provides a clear technical comparison relevant to research on transformer model architectures and positional encoding schemes. The data suggests several key findings:
1. **Superiority of Meta Architectures:** The models labeled "Meta" (likely referring to architectures from Meta AI Research) demonstrate a much higher capacity to learn the "Parity" task, especially when given sufficient training data (longer sequences). Their ability to reach perfect accuracy indicates the task is fully solvable by these models under the right conditions.
2. **Critical Role of Training Context Length:** The most significant factor for success appears to be matching the training sequence length to the evaluation length. All models show their best performance at train length 512, which matches the eval length. The "Meta" models show an especially strong dependence on this, with performance skyrocketing as training length increases.
3. **Architectural Efficiency:** "Meta + RoPE" shows better sample efficiency at the shortest training length (128) compared to "Meta + APE," suggesting that Rotary Positional Embeddings (RoPE) may provide a better inductive bias for learning positional relationships with limited data. However, with enough data (train length 512), both positional encoding methods (APE and RoPE) enable perfect task mastery.
4. **Baseline Model Limitations:** The GPT-2 and GPT-Neo-125M models plateau at around 54-60% accuracy, indicating they may lack the architectural capacity or appropriate inductive biases to fully solve this specific parity task, even with extended training. Their performance is essentially at a guessing or shallow pattern-matching level for this problem.
In summary, the chart is an empirical demonstration that for certain algorithmic tasks like parity, model architecture (specifically the "Meta" designs) and the alignment of training and evaluation context lengths are paramount for achieving high performance.