\n
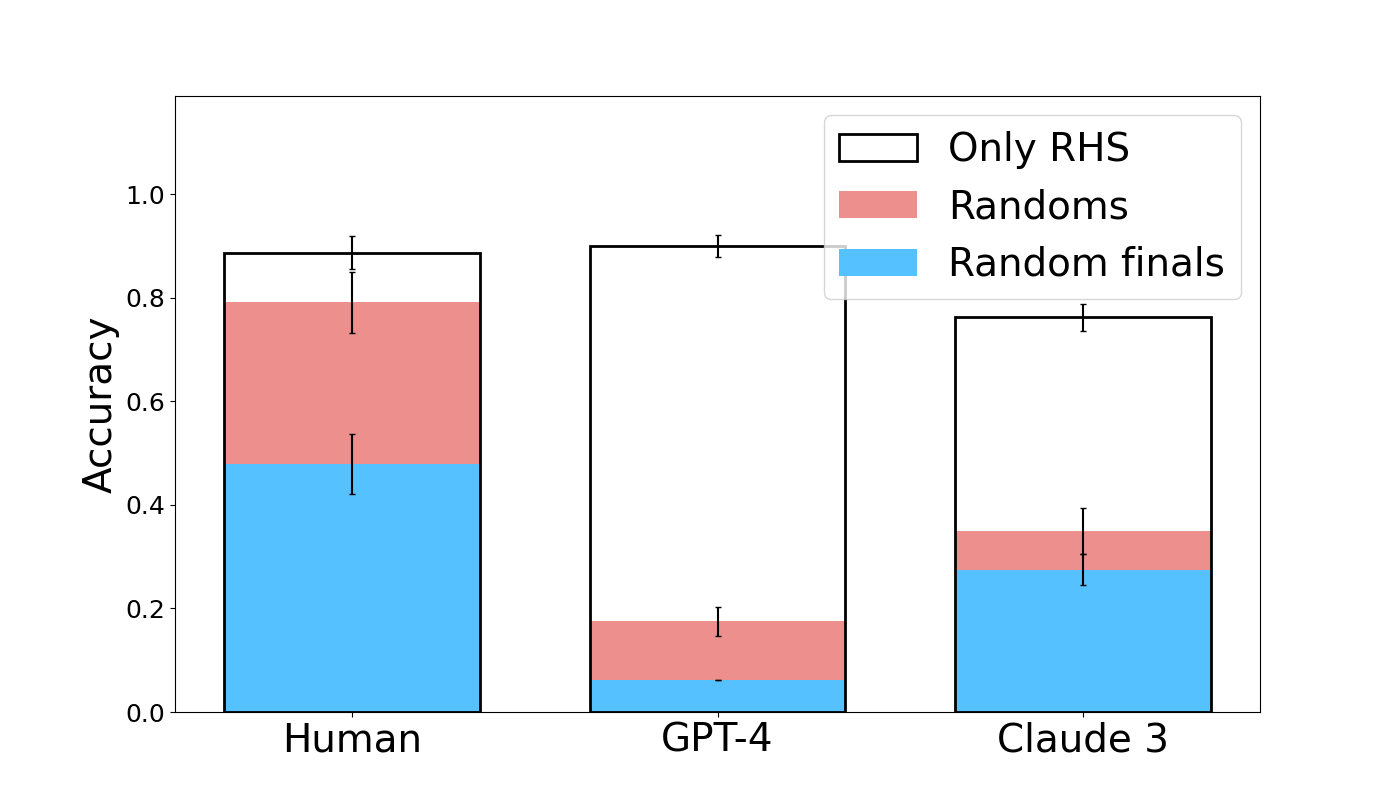
## Bar Chart: Accuracy Comparison of Human, GPT-4, and Claude 3
### Overview
This bar chart compares the accuracy of three entities – Human, GPT-4, and Claude 3 – across three different conditions: "Only RHS", "Randoms", and "Random finals". Accuracy is represented on the y-axis, and the entities are displayed on the x-axis. Each bar is a stacked bar, showing the contribution of each condition to the overall accuracy. Error bars are present on top of each bar, indicating the uncertainty in the accuracy measurements.
### Components/Axes
* **X-axis:** Entity - labeled "Human", "GPT-4", and "Claude 3".
* **Y-axis:** Accuracy - ranging from 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner.
* "Only RHS" - represented by a white fill with a black outline.
* "Randoms" - represented by a light red fill with a black outline.
* "Random finals" - represented by a light blue fill with a black outline.
* **Error Bars:** Black vertical lines extending above each bar, indicating standard error or confidence intervals.
### Detailed Analysis
The chart consists of three stacked bar groups, one for each entity. Each bar is divided into three sections corresponding to the legend categories.
**Human:**
* "Random finals" (light blue): Approximately 0.52 ± 0.06 (estimated from error bar range).
* "Randoms" (light red): Approximately 0.25 ± 0.06.
* "Only RHS" (white): Approximately 0.12 ± 0.06.
* Total Accuracy: Approximately 0.89 ± 0.06.
**GPT-4:**
* "Random finals" (light blue): Approximately 0.10 ± 0.04.
* "Randoms" (light red): Approximately 0.12 ± 0.04.
* "Only RHS" (white): Approximately 0.72 ± 0.04.
* Total Accuracy: Approximately 0.94 ± 0.04.
**Claude 3:**
* "Random finals" (light blue): Approximately 0.32 ± 0.06.
* "Randoms" (light red): Approximately 0.08 ± 0.06.
* "Only RHS" (white): Approximately 0.48 ± 0.06.
* Total Accuracy: Approximately 0.88 ± 0.06.
### Key Observations
* GPT-4 exhibits the highest accuracy overall, primarily driven by its performance in the "Only RHS" condition.
* Human accuracy is largely contributed by the "Random finals" and "Randoms" conditions.
* Claude 3 shows a more balanced contribution from all three conditions.
* The error bars suggest that the accuracy measurements for all entities and conditions have some degree of uncertainty.
* GPT-4 has a significantly higher "Only RHS" component than the other two.
### Interpretation
The data suggests that GPT-4 excels at tasks involving "Only RHS" (Right Hand Side), while humans perform better with "Random finals" and "Randoms". Claude 3 demonstrates a more consistent performance across all conditions. The stacked bar format effectively illustrates the composition of accuracy for each entity, highlighting the relative importance of each condition. The error bars indicate that the differences in accuracy between the entities may not always be statistically significant, but the trends are clear. The "Only RHS" condition might represent a specific type of reasoning or problem-solving that GPT-4 is particularly well-suited for, while humans may rely more on pattern recognition or intuition ("Randoms" and "Random finals"). The data could be used to inform the selection of the most appropriate entity for different types of tasks.