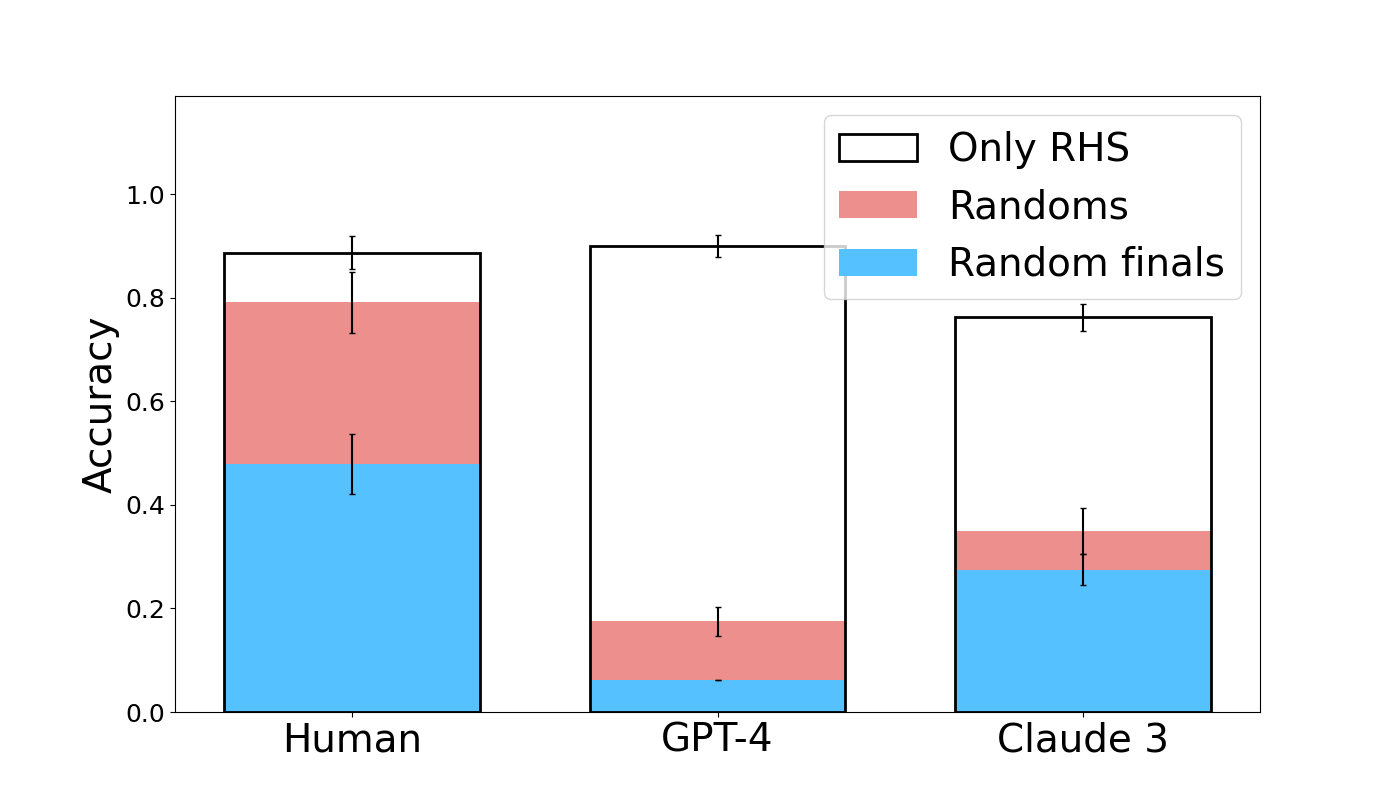
## Stacked Bar Chart: Accuracy Comparison Across Human and AI Models
### Overview
The image displays a stacked bar chart comparing the accuracy of three entities—Human, GPT-4, and Claude 3—across three distinct performance categories. The chart is designed to show the composition of overall accuracy for each entity, broken down into contributions from "Only RHS," "Randoms," and "Random finals."
### Components/Axes
* **Y-Axis:** Labeled "Accuracy," with a linear scale ranging from 0.0 to 1.0. Major tick marks are present at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:** Categorical, listing three groups: "Human," "GPT-4," and "Claude 3."
* **Legend:** Positioned in the top-right corner of the chart area. It defines three stacked components:
* **Only RHS:** Represented by a white bar segment with a black outline.
* **Randoms:** Represented by a pink/salmon-colored bar segment.
* **Random finals:** Represented by a light blue bar segment.
* **Error Bars:** Each colored segment within every bar has a vertical black error bar extending above and below its top edge, indicating variability or confidence intervals for that specific measurement.
### Detailed Analysis
The chart presents the following approximate accuracy values for each entity, decomposed by category. Values are estimated from the visual scale.
**1. Human**
* **Total Accuracy (Top of White Bar):** ~0.89
* **Component Breakdown (from bottom to top):**
* **Random finals (Blue):** ~0.48
* **Randoms (Pink):** ~0.31 (Cumulative height: ~0.79)
* **Only RHS (White):** ~0.10 (Cumulative height: ~0.89)
* **Trend:** The largest contributor to Human accuracy is "Random finals," followed by "Randoms." The "Only RHS" component is the smallest.
**2. GPT-4**
* **Total Accuracy (Top of White Bar):** ~0.90
* **Component Breakdown (from bottom to top):**
* **Random finals (Blue):** ~0.06
* **Randoms (Pink):** ~0.12 (Cumulative height: ~0.18)
* **Only RHS (White):** ~0.72 (Cumulative height: ~0.90)
* **Trend:** The vast majority of GPT-4's accuracy comes from the "Only RHS" component. The contributions from "Random finals" and "Randoms" are minimal.
**3. Claude 3**
* **Total Accuracy (Top of White Bar):** ~0.77
* **Component Breakdown (from bottom to top):**
* **Random finals (Blue):** ~0.28
* **Randoms (Pink):** ~0.07 (Cumulative height: ~0.35)
* **Only RHS (White):** ~0.42 (Cumulative height: ~0.77)
* **Trend:** Claude 3 shows a mixed profile. "Only RHS" is the largest single component, but "Random finals" also provides a substantial contribution. "Randoms" is the smallest component.
### Key Observations
1. **Divergent Strategies:** The three entities exhibit fundamentally different accuracy compositions. Humans rely heavily on "Random finals" and "Randoms," GPT-4 relies almost exclusively on "Only RHS," and Claude 3 uses a combination of both strategies.
2. **Performance Hierarchy:** In terms of total accuracy, GPT-4 (~0.90) and Human (~0.89) are nearly tied at the top, with Claude 3 (~0.77) performing lower.
3. **"Only RHS" Dominance in AI:** Both AI models (GPT-4 and Claude 3) derive a larger proportion of their accuracy from the "Only RHS" category compared to Humans.
4. **Error Bar Variability:** The error bars are most pronounced on the "Only RHS" segments for Human and GPT-4, suggesting greater uncertainty or variance in that specific measurement for those groups. The error bars on the smaller "Randoms" and "Random finals" segments for GPT-4 are relatively tight.
### Interpretation
This chart likely visualizes the results of a benchmark or experiment testing reasoning or problem-solving capabilities. The categories suggest different methods or information sources:
* **"Only RHS":** Possibly refers to using only the Right-Hand Side of an equation or a specific, constrained set of rules.
* **"Random finals" / "Randoms":** Suggest strategies involving randomness, guessing, or less deterministic approaches.
The data demonstrates that advanced AI models like GPT-4 can achieve human-level accuracy on this task, but they do so through a markedly different mechanism—leveraging a precise, rule-based approach ("Only RHS") rather than the more stochastic or heuristic methods ("Random finals"/"Randoms") that characterize human performance in this context. Claude 3 represents an intermediate state, blending both approaches but not excelling in either to the same degree as the specialists (Human in randomness, GPT-4 in rules). The high accuracy of GPT-4 with a low error bar on the "Only RHS" segment indicates a robust and reliable mastery of that specific method.