TECHNICAL ASSET FINGERPRINT
70cb8b493310545cdeb255eb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
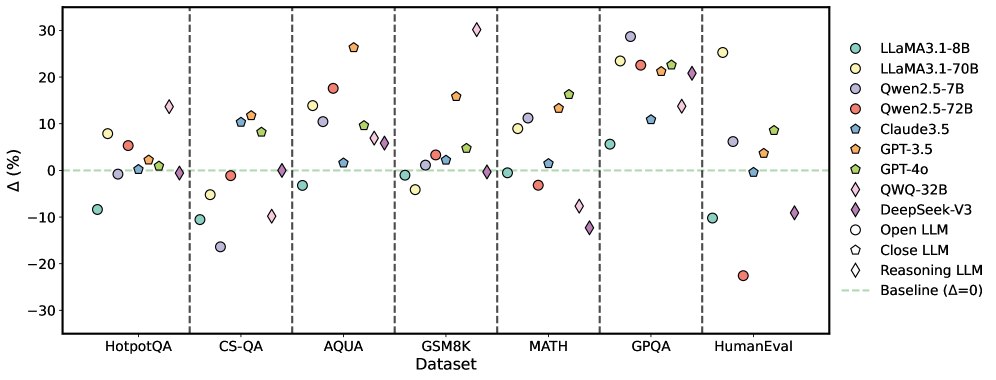
## Scatter Plot: Model Performance Across Datasets
### Overview
The image is a scatter plot comparing the performance of various large language models (LLMs) across different datasets. The y-axis represents the percentage difference (Δ) from a baseline, and the x-axis represents the datasets. Each model is represented by a unique color and marker.
### Components/Axes
* **X-axis:** "Dataset" with categories: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, HumanEval.
* **Y-axis:** "Δ (%)" with a numerical scale ranging from -30 to 30, with increments of 10.
* **Legend:** Located on the right side of the plot, mapping colors and markers to specific LLMs:
* Light Blue Circle: LLaMA3.1-8B
* Yellow Circle: LLaMA3.1-70B
* Light Purple Circle: Qwen2.5-7B
* Red Circle: Qwen2.5-72B
* Dark Blue Pentagon: Claude3.5
* Orange Pentagon: GPT-3.5
* Green Pentagon: GPT-4o
* Yellow Diamond: QWQ-32B
* Dark Purple Diamond: DeepSeek-V3
* White Circle: Open LLM
* White Pentagon: Close LLM
* White Diamond: Reasoning LLM
* Dashed Light Green Line: Baseline (Δ=0)
* Vertical dashed lines separate the datasets.
### Detailed Analysis
**HotpotQA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately -8%
* LLaMA3.1-70B (Yellow Circle): Approximately 8%
* Qwen2.5-7B (Light Purple Circle): Approximately 0%
* Qwen2.5-72B (Red Circle): Approximately 2%
* Claude3.5 (Dark Blue Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 10%
* GPT-4o (Green Pentagon): Approximately 5%
* QWQ-32B (Yellow Diamond): Approximately -2%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -20%
* Open LLM (White Circle): Approximately -10%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately -25%
**CS-QA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately -10%
* LLaMA3.1-70B (Yellow Circle): Approximately -5%
* Qwen2.5-7B (Light Purple Circle): Approximately 0%
* Qwen2.5-72B (Red Circle): Approximately -2%
* Claude3.5 (Dark Blue Pentagon): Approximately 0%
* GPT-3.5 (Orange Pentagon): Approximately 0%
* GPT-4o (Green Pentagon): Approximately 0%
* QWQ-32B (Yellow Diamond): Approximately 1%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -10%
* Open LLM (White Circle): Approximately -15%
* Close LLM (White Pentagon): Approximately -2%
* Reasoning LLM (White Diamond): Approximately 1%
**AQUA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 2%
* LLaMA3.1-70B (Yellow Circle): Approximately 8%
* Qwen2.5-7B (Light Purple Circle): Approximately 10%
* Qwen2.5-72B (Red Circle): Approximately 18%
* Claude3.5 (Dark Blue Pentagon): Approximately 15%
* GPT-3.5 (Orange Pentagon): Approximately 28%
* GPT-4o (Green Pentagon): Approximately 12%
* QWQ-32B (Yellow Diamond): Approximately 2%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -8%
* Open LLM (White Circle): Approximately 1%
* Close LLM (White Pentagon): Approximately 10%
* Reasoning LLM (White Diamond): Approximately 12%
**GSM8K Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 2%
* LLaMA3.1-70B (Yellow Circle): Approximately 0%
* Qwen2.5-7B (Light Purple Circle): Approximately 0%
* Qwen2.5-72B (Red Circle): Approximately 0%
* Claude3.5 (Dark Blue Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 17%
* GPT-4o (Green Pentagon): Approximately 2%
* QWQ-32B (Yellow Diamond): Approximately 0%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 0%
* Open LLM (White Circle): Approximately -5%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately -2%
**MATH Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 10%
* LLaMA3.1-70B (Yellow Circle): Approximately 12%
* Qwen2.5-7B (Light Purple Circle): Approximately 10%
* Qwen2.5-72B (Red Circle): Approximately 10%
* Claude3.5 (Dark Blue Pentagon): Approximately 10%
* GPT-3.5 (Orange Pentagon): Approximately 12%
* GPT-4o (Green Pentagon): Approximately 10%
* QWQ-32B (Yellow Diamond): Approximately 12%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -12%
* Open LLM (White Circle): Approximately 0%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately 15%
**GPQA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 22%
* LLaMA3.1-70B (Yellow Circle): Approximately 25%
* Qwen2.5-7B (Light Purple Circle): Approximately 20%
* Qwen2.5-72B (Red Circle): Approximately 22%
* Claude3.5 (Dark Blue Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 28%
* GPT-4o (Green Pentagon): Approximately 25%
* QWQ-32B (Yellow Diamond): Approximately 10%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 12%
* Open LLM (White Circle): Approximately 2%
* Close LLM (White Pentagon): Approximately 2%
* Reasoning LLM (White Diamond): Approximately 10%
**HumanEval Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately -10%
* LLaMA3.1-70B (Yellow Circle): Approximately 28%
* Qwen2.5-7B (Light Purple Circle): Approximately 10%
* Qwen2.5-72B (Red Circle): Approximately 2%
* Claude3.5 (Dark Blue Pentagon): Approximately 10%
* GPT-3.5 (Orange Pentagon): Approximately 10%
* GPT-4o (Green Pentagon): Approximately 10%
* QWQ-32B (Yellow Diamond): Approximately 10%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 10%
* Open LLM (White Circle): Approximately -22%
* Close LLM (White Pentagon): Approximately 0%
* Reasoning LLM (White Diamond): Approximately 10%
### Key Observations
* The performance of the models varies significantly across different datasets.
* GPT-3.5 generally performs well, often achieving high percentage differences.
* DeepSeek-V3 shows a wide range of performance, with some datasets showing negative percentage differences.
* The "Reasoning LLM" (White Diamond) shows a wide range of performance.
### Interpretation
The scatter plot provides a comparative analysis of various LLMs across different benchmark datasets. The percentage difference from the baseline indicates how much better or worse each model performs relative to a standard. The variability in performance across datasets suggests that different models are better suited for different types of tasks. For example, GPT-3.5 consistently performs well, indicating a robust general-purpose capability. In contrast, DeepSeek-V3's performance fluctuates, suggesting it may be highly specialized or sensitive to the nature of the task. The plot highlights the importance of evaluating LLMs on a diverse set of benchmarks to understand their strengths and weaknesses. The "Reasoning LLM" shows a wide range of performance, suggesting it may be highly specialized or sensitive to the nature of the task.
DECODING INTELLIGENCE...