## Chart: Training Loss, Wikitext103 Perplexity, and C4 Loss vs. Million Sequences
### Overview
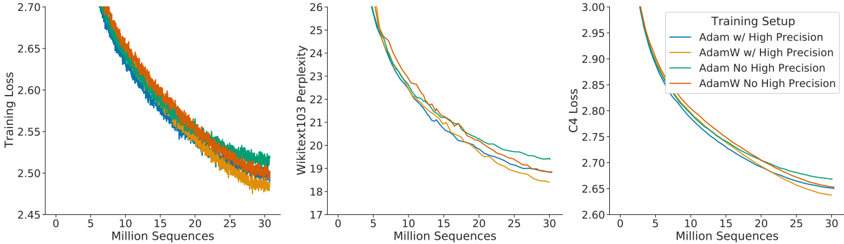
The image presents three line charts comparing the performance of different training setups (Adam w/ High Precision, AdamW w/ High Precision, Adam No High Precision, AdamW No High Precision) across three different metrics: Training Loss, Wikitext103 Perplexity, and C4 Loss. All charts share the same x-axis: Million Sequences.
### Components/Axes
**Chart 1: Training Loss**
* **Y-axis:** Training Loss, ranging from 2.45 to 2.70.
* **X-axis:** Million Sequences, ranging from 0 to 30.
* **Legend (Top-Right):**
* Blue: Adam w/ High Precision
* Yellow: AdamW w/ High Precision
* Green: Adam No High Precision
* Orange: AdamW No High Precision
**Chart 2: Wikitext103 Perplexity**
* **Y-axis:** Wikitext103 Perplexity, ranging from 17 to 26.
* **X-axis:** Million Sequences, ranging from 0 to 30.
* **Legend (Top-Right):** (Same as Chart 1)
* Blue: Adam w/ High Precision
* Yellow: AdamW w/ High Precision
* Green: Adam No High Precision
* Orange: AdamW No High Precision
**Chart 3: C4 Loss**
* **Y-axis:** C4 Loss, ranging from 2.60 to 3.00.
* **X-axis:** Million Sequences, ranging from 0 to 30.
* **Legend (Top-Right):** (Same as Chart 1)
* Blue: Adam w/ High Precision
* Yellow: AdamW w/ High Precision
* Green: Adam No High Precision
* Orange: AdamW No High Precision
### Detailed Analysis
**Chart 1: Training Loss**
* **Adam w/ High Precision (Blue):** Starts at approximately 2.70 and decreases to around 2.52 by 30 Million Sequences.
* **AdamW w/ High Precision (Yellow):** Starts at approximately 2.70 and decreases to around 2.49 by 30 Million Sequences.
* **Adam No High Precision (Green):** Starts at approximately 2.70 and decreases to around 2.52 by 30 Million Sequences.
* **AdamW No High Precision (Orange):** Starts at approximately 2.70 and decreases to around 2.50 by 30 Million Sequences.
**Trend:** All lines show a decreasing trend, indicating a reduction in training loss as the number of sequences increases.
**Chart 2: Wikitext103 Perplexity**
* **Adam w/ High Precision (Blue):** Starts at approximately 26 and decreases to around 20.5 by 30 Million Sequences.
* **AdamW w/ High Precision (Yellow):** Starts at approximately 26 and decreases to around 19.5 by 30 Million Sequences.
* **Adam No High Precision (Green):** Starts at approximately 26 and decreases to around 20.5 by 30 Million Sequences.
* **AdamW No High Precision (Orange):** Starts at approximately 26 and decreases to around 20 by 30 Million Sequences.
**Trend:** All lines show a decreasing trend, indicating a reduction in perplexity as the number of sequences increases.
**Chart 3: C4 Loss**
* **Adam w/ High Precision (Blue):** Starts at approximately 3.00 and decreases to around 2.68 by 30 Million Sequences.
* **AdamW w/ High Precision (Yellow):** Starts at approximately 3.00 and decreases to around 2.65 by 30 Million Sequences.
* **Adam No High Precision (Green):** Starts at approximately 3.00 and decreases to around 2.68 by 30 Million Sequences.
* **AdamW No High Precision (Orange):** Starts at approximately 3.00 and decreases to around 2.66 by 30 Million Sequences.
**Trend:** All lines show a decreasing trend, indicating a reduction in C4 loss as the number of sequences increases.
### Key Observations
* All four training setups show a decrease in Training Loss, Wikitext103 Perplexity, and C4 Loss as the number of training sequences increases.
* The AdamW optimizer, both with and without high precision, generally performs slightly better (lower loss/perplexity) than the Adam optimizer.
* The difference between using high precision and not using high precision is relatively small.
### Interpretation
The charts demonstrate the learning curves of different training setups using Adam and AdamW optimizers, with and without high precision, on three different metrics. The decreasing trends in all charts indicate that the models are learning effectively as they are exposed to more training data. The AdamW optimizer appears to provide a slight advantage over the Adam optimizer in terms of achieving lower loss and perplexity. The impact of high precision on the training process seems to be minimal, suggesting that it may not be a critical factor in this particular scenario.