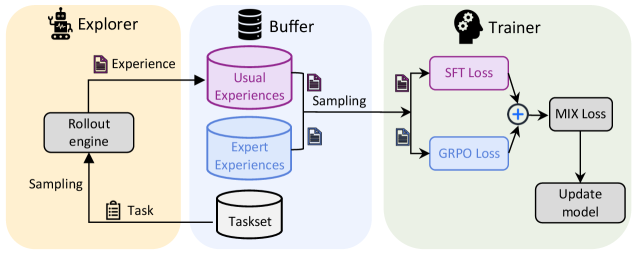
## Diagram: Reinforcement Learning System Architecture
### Overview
The diagram illustrates a three-stage pipeline for a reinforcement learning (RL) system: **Explorer**, **Buffer**, and **Trainer**. Arrows indicate data flow and interactions between components, with distinct color-coded sections for each stage.
### Components/Axes
#### Explorer (Left Section, Peach Background)
- **Rollout engine**: Generates experiences via interaction with a task.
- **Sampling**: Arrows indicate data extraction from the rollout engine.
- **Task**: Represents the environment or problem domain.
#### Buffer (Middle Section, Light Blue Background)
- **Usual Experiences**: Stored in a pink cylinder, representing standard data.
- **Expert Experiences**: Stored in a blue cylinder, representing high-quality or pre-trained data.
- **Sampling**: Arrows indicate data extraction for training.
- **Taskset**: A gray cylinder representing a collection of tasks.
#### Trainer (Right Section, Light Green Background)
- **SFT Loss**: Supervised Fine-Tuning loss, represented in pink.
- **GRPO Loss**: Group Relative Policy Optimization loss, represented in blue.
- **MIX Loss**: Combined loss function (SFT + GRPO), represented in gray.
- **Update model**: Final step to refine the model using MIX Loss.
### Detailed Analysis
1. **Explorer**:
- The rollout engine interacts with a task to generate experiences.
- Sampling extracts these experiences for storage in the Buffer.
2. **Buffer**:
- Experiences are categorized into "Usual" (pink) and "Expert" (blue) and stored separately.
- Sampling from both categories feeds data into the Trainer.
3. **Trainer**:
- SFT Loss and GRPO Loss are computed independently and combined via a summation node (+) to form MIX Loss.
- MIX Loss drives the model update process.
### Key Observations
- **Flow Direction**: Data moves unidirectionally from Explorer → Buffer → Trainer.
- **Loss Function Design**: The Trainer integrates SFT (supervised learning) and GRPO (RL-specific) losses, suggesting a hybrid optimization strategy.
- **Buffer Segmentation**: Separating "Usual" and "Expert" experiences implies a focus on balancing exploration and leveraging prior knowledge.
### Interpretation
This architecture represents a **meta-RL** or **multi-task RL** system where:
- The **Explorer** collects diverse experiences across tasks.
- The **Buffer** acts as a memory bank, preserving both standard and expert trajectories to mitigate catastrophic forgetting.
- The **Trainer** uses a mixed loss function to balance supervised learning (SFT) and RL objectives (GRPO), enabling efficient adaptation to new tasks while retaining expertise.
The system emphasizes **sample efficiency** (via expert experiences) and **generalization** (via mixed loss), critical for real-world RL applications. The absence of explicit numerical values suggests a conceptual framework rather than empirical results.