## System Diagram: Reinforcement Learning Training Pipeline
### Overview
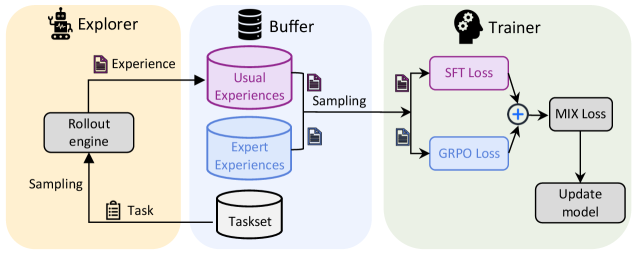
The image is a system diagram illustrating a reinforcement learning training pipeline. It depicts the flow of data and processes between three main components: an Explorer, a Buffer, and a Trainer. The diagram shows how experience is generated, stored, sampled, and used to update a model.
### Components/Axes
* **Explorer (Left, Yellow Background):**
* Icon: A robot-like figure.
* Function: Generates experience by interacting with an environment.
* Output: "Experience" (represented by a document icon).
* Component: "Rollout engine" (grey box).
* Input to Rollout engine: "Task" (represented by a document icon).
* Sampling: The Rollout engine samples from the Task.
* **Buffer (Center, Blue Background):**
* Icon: Database icon.
* Function: Stores and samples experiences.
* Components:
* "Usual Experiences" (purple cylinder).
* "Expert Experiences" (blue cylinder).
* "Taskset" (grey cylinder).
* Input: Experience from the Explorer.
* Output: Sampling to the Trainer.
* **Trainer (Right, Green Background):**
* Icon: Head with gears.
* Function: Updates the model based on sampled experiences.
* Inputs:
* "SFT Loss" (purple box).
* "GRPO Loss" (blue box).
* Process: "+" (addition) of SFT Loss and GRPO Loss.
* Output: "MIX Loss" (grey box).
* Final Step: "Update model" (grey box).
### Detailed Analysis or ### Content Details
* **Explorer:** The Explorer uses a "Rollout engine" to generate "Experience" based on a "Task". The Rollout engine samples from the Task.
* **Buffer:** The Buffer stores "Usual Experiences" and "Expert Experiences" separately. Both types of experiences are sampled and sent to the Trainer. The Buffer also contains a "Taskset".
* **Trainer:** The Trainer receives sampled experiences and calculates "SFT Loss" and "GRPO Loss". These losses are combined ("+") to produce a "MIX Loss", which is then used to "Update model".
### Key Observations
* The diagram highlights the separation of experience types (Usual vs. Expert) in the Buffer.
* The Trainer combines two different loss functions (SFT and GRPO) to create a mixed loss for model updating.
* The flow of data is unidirectional, from Explorer to Buffer to Trainer.
### Interpretation
The diagram illustrates a reinforcement learning training pipeline that leverages both usual and expert experiences to train a model. The separation of experience types in the Buffer suggests that the system may be designed to incorporate expert knowledge or demonstrations into the learning process. The combination of SFT and GRPO losses in the Trainer indicates that the model is being optimized using multiple objectives or constraints. This setup could be used to improve the model's performance, robustness, or safety. The diagram provides a high-level overview of the system's architecture and data flow, which can be useful for understanding the training process and identifying potential areas for improvement.