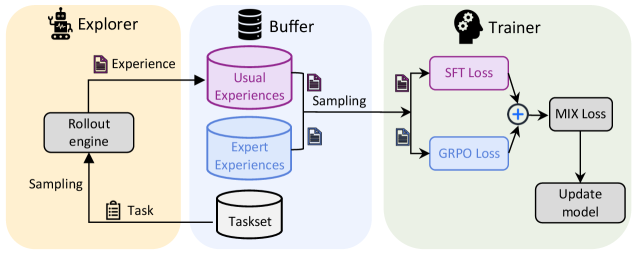
## System Architecture Diagram: Reinforcement Learning Training Pipeline
### Overview
The image is a technical system architecture diagram illustrating a three-stage pipeline for training a machine learning model, likely a reinforcement learning agent. The diagram is divided into three distinct, color-coded sections representing different functional modules: **Explorer** (yellow background), **Buffer** (light blue background), and **Trainer** (light green background). The flow of data and processes moves from left to right.
### Components/Axes
The diagram is not a chart with axes but a flow diagram with labeled components and directional arrows.
**1. Explorer Module (Left, Yellow Background)**
* **Icon:** A robot head.
* **Title:** `Explorer`
* **Components:**
* `Rollout engine`: A central processing unit.
* `Task`: An input represented by a clipboard icon.
* **Flow:**
* An arrow labeled `Sampling` points from the `Task` input to the `Rollout engine`.
* An arrow labeled `Experience` (with a document icon) points from the `Rollout engine` to the `Buffer` module.
**2. Buffer Module (Center, Light Blue Background)**
* **Icon:** A database cylinder.
* **Title:** `Buffer`
* **Components:**
* `Usual Experiences`: A pink cylinder.
* `Expert Experiences`: A blue cylinder.
* `Taskset`: A white cylinder at the bottom.
* **Flow:**
* The `Experience` arrow from the Explorer feeds into the `Usual Experiences` cylinder.
* An arrow labeled `Sampling` (with a document icon) points from both the `Usual Experiences` and `Expert Experiences` cylinders to the `Trainer` module.
* An arrow points from the `Taskset` cylinder to the `Task` input in the Explorer module, indicating task sourcing.
**3. Trainer Module (Right, Light Green Background)**
* **Icon:** A head with gears.
* **Title:** `Trainer`
* **Components:**
* `SFT Loss`: A pink box.
* `GRPO Loss`: A blue box.
* `MIX Loss`: A gray box.
* `Update model`: A gray box.
* **Flow:**
* Two arrows from the Buffer's `Sampling` step feed into the Trainer. One goes to `SFT Loss` and the other to `GRPO Loss`.
* The outputs of `SFT Loss` and `GRPO Loss` converge at a circle with a plus sign (`+`), indicating summation or combination.
* The result of this combination flows into `MIX Loss`.
* The output of `MIX Loss` flows into `Update model`.
### Detailed Analysis
The diagram depicts a closed-loop training system:
1. **Task Initiation:** A `Task` is drawn from the `Taskset` in the Buffer and sent to the Explorer.
2. **Experience Generation:** The Explorer's `Rollout engine` executes the task, generating `Experience` data.
3. **Experience Storage:** This experience is stored in the Buffer, specifically in the `Usual Experiences` repository.
4. **Training Data Sampling:** The Trainer samples data from both `Usual Experiences` and a separate repository of `Expert Experiences`.
5. **Dual-Loss Training:** The sampled data is used to compute two distinct loss functions:
* `SFT Loss` (likely Supervised Fine-Tuning Loss).
* `GRPO Loss` (likely a variant of Policy Optimization Loss, such as Generalized Reinforcement Policy Optimization).
6. **Loss Combination & Model Update:** The two losses are combined into a `MIX Loss`, which is then used to `Update model`. The updated model presumably informs future rollouts, completing the cycle.
### Key Observations
* **Color-Coding Consistency:** The color of the loss boxes (`SFT Loss` - pink, `GRPO Loss` - blue) matches the color of the experience cylinders they primarily sample from (`Usual Experiences` - pink, `Expert Experiences` - blue). This visually reinforces the data source for each loss component.
* **Separation of Experience Types:** The system explicitly separates `Usual Experiences` (generated by its own explorer) from `Expert Experiences` (presumably from an external or pre-collected source), suggesting a hybrid training approach.
* **Centralized Buffer:** The `Buffer` acts as the central hub, managing both the task supply and the experience repositories for training.
* **Composite Objective:** The final training signal (`MIX Loss`) is not a single objective but a combination of two different learning signals (SFT and GRPO).
### Interpretation
This diagram illustrates a sophisticated reinforcement learning or imitation learning framework designed for iterative improvement. The architecture suggests a system that learns from both its own interactions (`Usual Experiences` via `SFT Loss`) and from high-quality demonstrations (`Expert Experiences` via `GRPO Loss`). The `MIX Loss` indicates a multi-objective optimization strategy, potentially balancing stability (from supervised learning on expert data) with exploration and policy improvement (from reinforcement learning on its own experiences).
The pipeline is cyclical and self-reinforcing: the model updated by the Trainer will be used in the next iteration of the Rollout engine, generating new experiences to fill the buffer. The inclusion of a `Taskset` implies the system can be trained on a curriculum or distribution of tasks. This design is characteristic of advanced agent training systems aiming for robust and sample-efficient learning by leveraging both expert guidance and autonomous exploration.