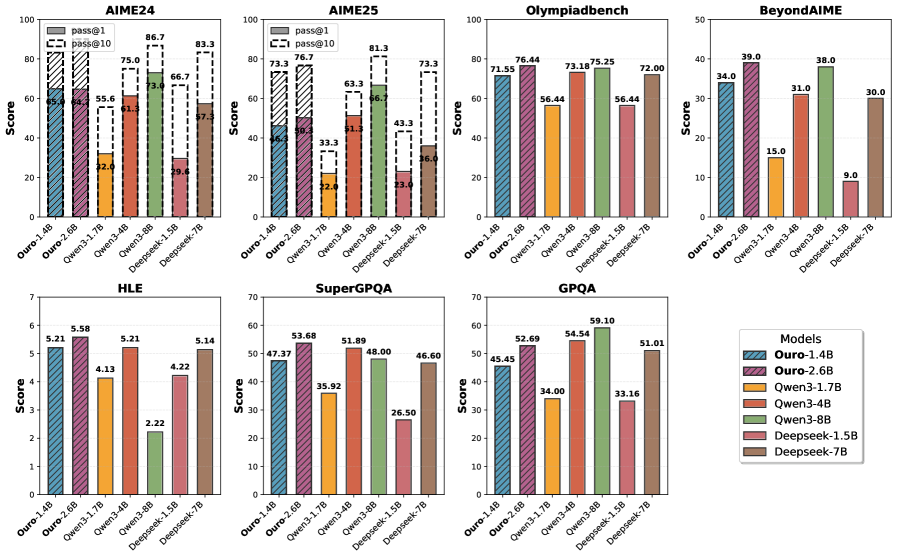
## Bar Chart: Model Performance Across Datasets
### Overview
The image contains seven grouped bar charts comparing the performance of seven AI models (Ouro-1.4B, Ouro-2.6B, Owen3-1.7B, Owen3-3.4B, Owen3-3.8B, Deepseek-1.5B, Deepseek-7B) across seven datasets (AIME24, AIME25, Olympiadbench, BeyondAIMe, HLE, SuperGPQA, GPQA). Scores range from 0 to 100, with numerical values displayed on top of each bar.
### Components/Axes
- **X-axis**: Datasets (AIME24, AIME25, Olympiadbench, BeyondAIMe, HLE, SuperGPQA, GPQA)
- **Y-axis**: Score (0–100)
- **Legend**: Located in the bottom-right corner, mapping colors to models:
- Ouro-1.4B: Blue
- Ouro-2.6B: Purple
- Owen3-1.7B: Orange
- Owen3-3.4B: Green
- Owen3-3.8B: Red
- Deepseek-1.5B: Pink
- Deepseek-7B: Brown
- **Bar Groups**: Each dataset chart groups bars by model, with consistent color coding across all charts.
### Detailed Analysis
#### AIME24
- Ouro-2.6B (purple): 64.0 (highest)
- Owen3-3.8B (red): 61.3
- Deepseek-7B (brown): 22.0 (lowest)
#### AIME25
- Owen3-3.8B (red): 66.7 (highest)
- Ouro-2.6B (purple): 63.3
- Deepseek-7B (brown): 23.0
#### Olympiadbench
- Ouro-2.6B (purple): 76.44 (highest)
- Owen3-3.8B (red): 73.18
- Deepseek-7B (brown): 56.44
#### BeyondAIMe
- Owen3-3.8B (red): 39.0 (highest)
- Ouro-2.6B (purple): 34.0
- Deepseek-1.5B (pink): 9.0 (lowest)
#### HLE
- Owen3-3.4B (green): 5.21 (highest)
- Deepseek-1.5B (pink): 2.22 (lowest)
#### SuperGPQA
- Owen3-3.8B (red): 51.89 (highest)
- Ouro-2.6B (purple): 47.37
- Deepseek-7B (brown): 26.50
#### GPQA
- Owen3-3.8B (red): 59.10 (highest)
- Ouro-2.6B (purple): 54.54
- Deepseek-7B (brown): 51.01
### Key Observations
1. **Owen3-3.8B (red)** consistently performs well across most datasets, particularly in AIME25 (66.7) and GPQA (59.10).
2. **Ouro-2.6B (purple)** excels in Olympiadbench (76.44) but underperforms in BeyondAIMe (34.0).
3. **Deepseek-7B (brown)** shows mixed results, with strong performance in GPQA (51.01) but poor results in BeyondAIMe (30.0).
4. **Deepseek-1.5B (pink)** has the lowest score in BeyondAIMe (9.0), suggesting significant dataset-specific limitations.
5. **Owen3-3.4B (green)** dominates HLE (5.21) but underperforms in other datasets.
### Interpretation
The data reveals that model performance is highly dataset-dependent. Owen3-3.8B demonstrates robustness across diverse tasks, while Ouro-2.6B excels in Olympiadbench, possibly due to specialized training. Deepseek models show variability, with the 7B version performing better in GPQA but struggling in BeyondAIMe. The stark drop in Deepseek-1.5B's score in BeyondAIMe (9.0) suggests potential architectural or training mismatches for that dataset. These trends highlight the importance of dataset-specific evaluation in AI model development and the need for models to generalize across tasks.