TECHNICAL ASSET FINGERPRINT
732290044da54c235ca22287
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
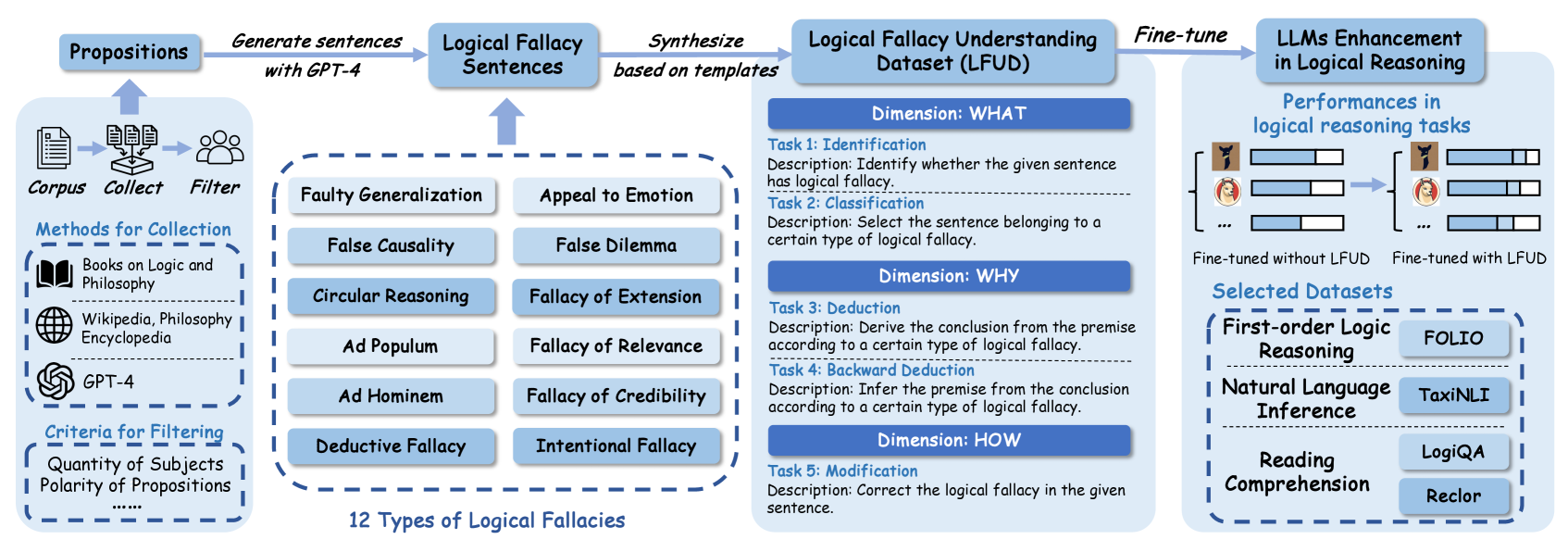
## Diagram: Logical Fallacy Dataset Creation and LLM Enhancement Pipeline
### Overview
This image is a technical flowchart illustrating a multi-stage process for creating a "Logical Fallacy Understanding Dataset (LFUD)" and using it to fine-tune Large Language Models (LLMs) to improve their performance in logical reasoning tasks. The diagram flows from left to right, detailing data sourcing, fallacy categorization, dataset construction, and final model evaluation.
### Components/Axes
The diagram is segmented into four primary vertical sections, connected by arrows indicating process flow.
**1. Left Section: Data Collection & Filtering**
* **Header:** "Corpus" with icons for documents, collection, and people.
* **Sub-header:** "Methods for Collection"
* "Books on Logic and Philosophy" (with book icon)
* "Wikipedia, Philosophy Encyclopedia" (with globe icon)
* "GPT-4" (with OpenAI logo icon)
* **Sub-header:** "Criteria for Filtering"
* "Quantity of Subjects"
* "Polarity of Propositions"
* "......" (indicating additional criteria)
* **Flow:** An arrow points from this section to the next, labeled "Generate sentences with GPT-4".
**2. Middle-Left Section: Fallacy Types & Sentence Generation**
* **Header:** "Logical Fallacy Sentences" (receives input from the previous step).
* **Central Block:** A dashed box containing a 2x6 grid of 12 logical fallacy types:
* Faulty Generalization, Appeal to Emotion
* False Causality, False Dilemma
* Circular Reasoning, Fallacy of Extension
* Ad Populum, Fallacy of Relevance
* Ad Hominem, Fallacy of Credibility
* Deductive Fallacy, Intentional Fallacy
* **Label below grid:** "12 Types of Logical Fallacies".
* **Flow:** An arrow points from this section to the next, labeled "Synthesize based on templates".
**3. Middle-Right Section: Dataset Structure (LFUD)**
* **Header:** "Logical Fallacy Understanding Dataset (LFUD)".
* **Structure:** Organized into three "Dimensions," each containing specific tasks.
* **Dimension: WHAT**
* **Task 1: Identification**
* Description: "Identify whether the given sentence has logical fallacy."
* **Task 2: Classification**
* Description: "Select the sentence belonging to a certain type of logical fallacy."
* **Dimension: WHY**
* **Task 3: Deduction**
* Description: "Derive the conclusion from the premise according to a certain type of logical fallacy."
* **Task 4: Backward Deduction**
* Description: "Infer the premise from the conclusion according to a certain type of logical fallacy."
* **Dimension: HOW**
* **Task 5: Modification**
* Description: "Correct the logical fallacy in the given sentence."
* **Flow:** An arrow points from this section to the final section, labeled "Fine-tune".
**4. Right Section: Model Enhancement & Evaluation**
* **Header:** "LLMs Enhancement in Logical Reasoning".
* **Sub-section:** "Performances in logical reasoning tasks"
* Visual comparison of two model states using bar charts (represented by icons and bars).
* Left side: "Fine-tuned without LFUD" (shows lower performance bars).
* Right side: "Fine-tuned with LFUD" (shows higher performance bars).
* **Sub-section:** "Selected Datasets" (for evaluation)
* **First-order Logic Reasoning:** "FOLIO"
* **Natural Language Inference:** "TaxiNLI"
* **Reading Comprehension:** "LogiQA", "Reclor"
### Detailed Analysis
The process is a pipeline:
1. **Input:** Raw text corpus from philosophy books, encyclopedias, and GPT-4.
2. **Processing:** The corpus is filtered based on subject quantity and proposition polarity. GPT-4 is then used to generate sentences containing logical fallacies.
3. **Categorization:** These sentences are categorized into 12 specific types of logical fallacies.
4. **Dataset Synthesis:** Using templates, the categorized sentences are synthesized into the structured LFUD dataset, which contains five distinct tasks across three conceptual dimensions (WHAT, WHY, HOW).
5. **Application:** The LFUD dataset is used to fine-tune LLMs.
6. **Evaluation:** The fine-tuned models are evaluated on their performance across four established logical reasoning benchmark datasets (FOLIO, TaxiNLI, LogiQA, Reclor), with the diagram indicating improved performance when using LFUD.
### Key Observations
* The diagram explicitly names GPT-4 as both a source for the initial corpus and the tool for generating fallacy sentences.
* The 12 fallacy types are presented in a specific grid layout, suggesting a comprehensive taxonomy.
* The LFUD dataset is not a simple list of examples; it's a multi-task learning resource designed to teach models to identify, classify, reason about, and correct fallacies.
* The evaluation section contrasts model performance "without LFUD" versus "with LFUD," visually asserting the dataset's value.
* The selected evaluation datasets cover different facets of logical reasoning: formal logic (FOLIO), natural language inference (TaxiNLI), and reading comprehension with reasoning (LogiQA, Reclor).
### Interpretation
This diagram outlines a methodology for addressing a key weakness in LLMs: robust logical reasoning. The core hypothesis is that by explicitly training models on a structured dataset of logical fallacies (LFUD), their general reasoning capabilities can be enhanced.
The process is **Peircean** in its investigative approach:
1. **Abduction:** It starts with the observation that LLMs struggle with logic and hypothesizes that teaching them fallacies (a form of "negative knowledge") will improve them.
2. **Deduction:** It logically designs a pipeline to create a training resource (LFUD) with specific tasks (Identification, Classification, Deduction, etc.) that should, in theory, impart this knowledge.
3. **Induction:** It tests the hypothesis by fine-tuning models and measuring performance on benchmark datasets, expecting to see a positive correlation between LFUD training and improved scores.
The "reading between the lines" suggests that traditional training data may lack explicit, structured logical reasoning examples. LFUD fills this gap by providing synthetic, template-based examples that isolate and teach the structure of flawed reasoning. The inclusion of a "Modification" task (Task 5) is particularly insightful, as it moves beyond passive recognition to active correction, potentially leading to deeper model understanding. The ultimate goal, as implied by the final evaluation block, is not just to recognize fallacies in isolation but to transfer this skill to broader reasoning tasks like inference and comprehension.
DECODING INTELLIGENCE...