## Flowchart: Model Training Pipeline
### Overview
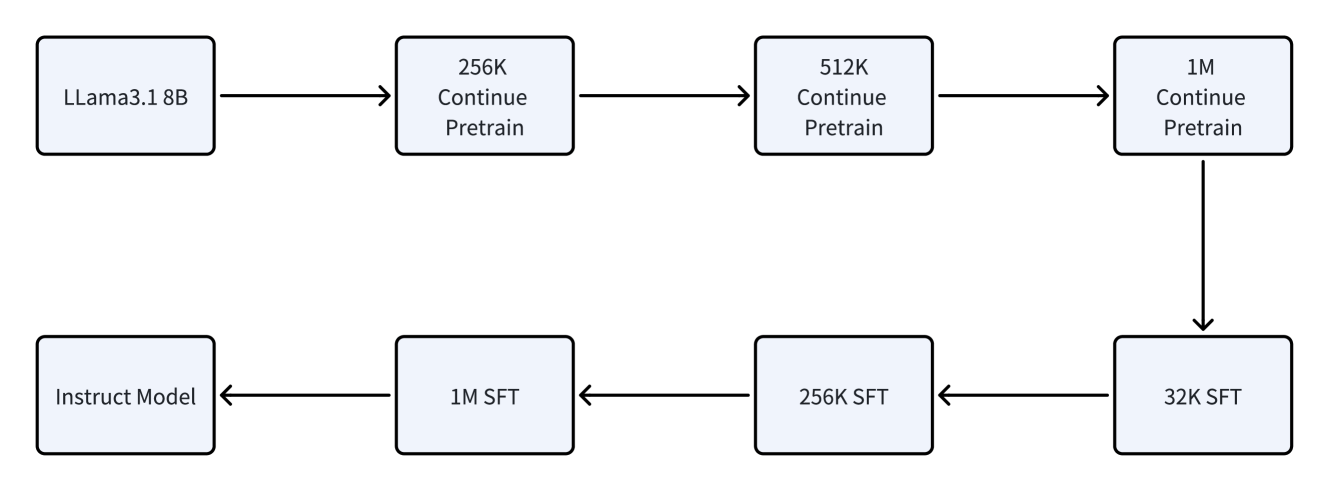
The diagram illustrates a two-path training pipeline for a language model, showing progression through different scales of data and training phases. Two parallel tracks exist: one for "Continue Pretrain" and another for "SFT" (Supervised Fine-Tuning), with a connection point at the 1M scale.
### Components/Axes
- **Nodes**:
- LLama3.1 8B (starting point)
- 256K Continue Pretrain
- 512K Continue Pretrain
- 1M Continue Pretrain
- Instruct Model (starting point for SFT)
- 1M SFT
- 256K SFT
- 32K SFT
- **Arrows**:
- Unidirectional flow indicators
- Connection between 1M Continue Pretrain and 1M SFT
### Detailed Analysis
1. **Continue Pretrain Path**:
- Starts at LLama3.1 8B (base model)
- Progresses through increasing data scales: 256K → 512K → 1M
- All nodes labeled "Continue Pretrain"
2. **SFT Path**:
- Starts at "Instruct Model"
- Progresses through decreasing data scales: 1M → 256K → 32K
- All nodes labeled "SFT"
3. **Connection Point**:
- 1M Continue Pretrain directly connects to 1M SFT
- Suggests transition from pretraining to fine-tuning at maximum scale
### Key Observations
- Pretraining scales increase logarithmically (8B → 256K → 512K → 1M)
- SFT scales decrease exponentially (1M → 256K → 32K)
- 1M scale acts as a bridge between pretraining and fine-tuning phases
- No feedback loops or parallel processing indicated
- All connections are linear and sequential
### Interpretation
This diagram represents a structured model development pipeline where:
1. **Pretraining Phase**: Begins with a base model (LLama3.1 8B) and progressively increases training data scale to 1M tokens, suggesting iterative refinement of model capabilities.
2. **Fine-Tuning Phase**: Starts at the same 1M scale but then reduces data size for specialized instruction tuning, indicating a focus on quality over quantity in later stages.
3. **Architectural Insight**: The 1M connection point implies that the most comprehensive pretraining serves as the foundation for subsequent fine-tuning, emphasizing the importance of large-scale unsupervised learning before specialized adaptation.
4. **Efficiency Consideration**: The decreasing SFT scales may reflect resource optimization strategies, using smaller datasets for final tuning after establishing base capabilities through extensive pretraining.
The pipeline demonstrates a deliberate progression from broad capability development to targeted specialization, with careful scaling decisions at each stage.