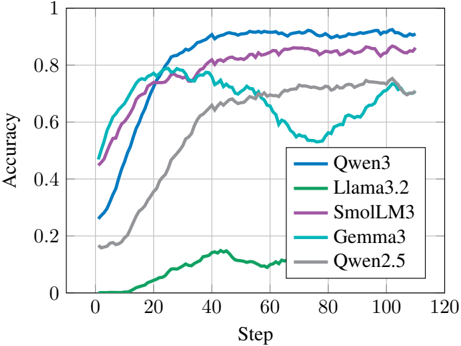
## Line Chart: Model Accuracy vs. Step
### Overview
The image is a line chart comparing the accuracy of five different language models (Qwen3, Llama3.2, SmolLM3, Gemma3, and Qwen2.5) over a number of steps. The chart shows how the accuracy of each model changes as the training progresses.
### Components/Axes
* **X-axis:** "Step", ranging from 0 to 120 in increments of 20.
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2.
* **Legend:** Located in the bottom-right corner, mapping model names to line colors:
* Qwen3: Blue
* Llama3.2: Green
* SmolLM3: Purple
* Gemma3: Teal
* Qwen2.5: Gray
### Detailed Analysis
* **Qwen3 (Blue):** Starts at approximately 0.26 accuracy at step 0, increases rapidly to around 0.8 at step 20, and then plateaus around 0.92 for the remaining steps.
* **Llama3.2 (Green):** Starts at approximately 0 accuracy at step 0, increases slowly to around 0.15 at step 40, and then remains relatively flat around 0.12 for the remaining steps.
* **SmolLM3 (Purple):** Starts at approximately 0.45 accuracy at step 0, increases rapidly to around 0.8 at step 20, and then plateaus around 0.85 for the remaining steps.
* **Gemma3 (Teal):** Starts at approximately 0.45 accuracy at step 0, increases rapidly to around 0.75 at step 20, and then fluctuates between 0.6 and 0.8 for the remaining steps.
* **Qwen2.5 (Gray):** Starts at approximately 0.16 accuracy at step 0, increases gradually to around 0.7 at step 60, and then fluctuates between 0.6 and 0.75 for the remaining steps.
### Key Observations
* Qwen3 achieves the highest accuracy and plateaus early in the training process.
* Llama3.2 performs significantly worse than the other models, with a very low accuracy throughout the training.
* SmolLM3 performs well, reaching a high accuracy and maintaining it throughout the training.
* Gemma3 and Qwen2.5 show similar performance, with a gradual increase in accuracy and some fluctuations.
### Interpretation
The chart demonstrates the performance of different language models during training. Qwen3 and SmolLM3 appear to be the most effective models based on this data, achieving high accuracy early in the training process. Llama3.2's poor performance suggests potential issues with its architecture, training data, or hyperparameters. Gemma3 and Qwen2.5 show moderate performance, indicating they may require further optimization or a different training approach to reach the same level of accuracy as Qwen3 and SmolLM3. The fluctuations in Gemma3 and Qwen2.5's accuracy after step 20 could be due to overfitting or instability in the training process.