\n
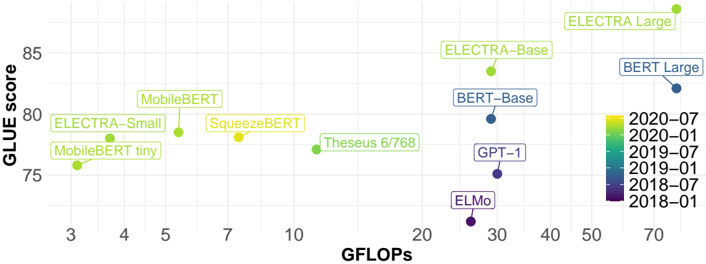
## Scatter Plot: GLUE Score vs. GFLOPs for Language Models
### Overview
This image presents a scatter plot comparing the performance (GLUE score) of various language models against their computational cost (GFLOPs - Giga Floating Point Operations per second). Each point on the plot represents a specific language model. The color of each point indicates the date of the model's release.
### Components/Axes
* **X-axis:** GFLOPs (ranging from approximately 3 to 70).
* **Y-axis:** GLUE score (ranging from approximately 74 to 86).
* **Data Points:** Represent individual language models.
* **Legend:** Located in the bottom-right corner, color-coded by release date:
* 2020-07 (Yellow)
* 2020-01 (Light Green)
* 2019-07 (Green)
* 2019-01 (Blue-Green)
* 2018-07 (Blue)
* 2018-01 (Dark Purple)
* **Models Labeled:** ELECTRA Large, ELECTRA-Base, BERT Large, BERT-Base, GPT-1, ELMo, Theseus 6/768, SqueezeBERT, MobileBERT, ELECTRA-Small, MobileBERT tiny.
### Detailed Analysis
The plot shows a general trend of higher GLUE scores correlating with higher GFLOPs, but with significant variation.
Here's a breakdown of the approximate data points, cross-referencing with the legend for color accuracy:
* **MobileBERT tiny:** Approximately (4 GFLOPs, 75 GLUE score) - Yellow (2020-07)
* **MobileBERT:** Approximately (5 GFLOPs, 79 GLUE score) - Light Green (2020-01)
* **ELECTRA-Small:** Approximately (6 GFLOPs, 77 GLUE score) - Yellow (2020-07)
* **SqueezeBERT:** Approximately (7 GFLOPs, 80 GLUE score) - Yellow (2020-07)
* **Theseus 6/768:** Approximately (10 GFLOPs, 79 GLUE score) - Light Green (2020-01)
* **ELECTRA-Base:** Approximately (22 GFLOPs, 83 GLUE score) - Green (2019-07)
* **BERT-Base:** Approximately (30 GFLOPs, 82 GLUE score) - Blue-Green (2019-01)
* **GPT-1:** Approximately (30 GFLOPs, 78 GLUE score) - Blue-Green (2019-01)
* **ELMo:** Approximately (30 GFLOPs, 75 GLUE score) - Blue (2018-07)
* **BERT Large:** Approximately (70 GFLOPs, 82 GLUE score) - Blue (2018-07)
* **ELECTRA Large:** Approximately (50 GFLOPs, 85 GLUE score) - Yellow (2020-07)
The trend for ELECTRA models is generally upward as the model size increases (tiny -> small -> base -> large). BERT models also show an increase in GLUE score with increased GFLOPs (Base -> Large).
### Key Observations
* **Release Date Correlation:** Newer models (released in 2020) tend to achieve higher GLUE scores for a given number of GFLOPs, suggesting improvements in model architecture or training techniques.
* **ELMo Outlier:** ELMo, released in 2018, has a relatively low GLUE score compared to models released in later years with similar GFLOPs.
* **ELECTRA Large Performance:** ELECTRA Large achieves the highest GLUE score in the dataset.
* **GPT-1 Performance:** GPT-1 has a relatively low GLUE score compared to other models with similar GFLOPs.
### Interpretation
The data suggests a trade-off between model performance (GLUE score) and computational cost (GFLOPs). While increasing the number of GFLOPs generally leads to higher performance, the efficiency of models has improved over time. Newer models, like ELECTRA, achieve better performance with fewer GFLOPs than older models like ELMo. This indicates advancements in model design and training methodologies.
The plot highlights the importance of considering both performance and efficiency when selecting a language model for a specific application. The release date provides a temporal context, showing the evolution of language models and the progress made in the field. The outliers, such as ELMo and GPT-1, suggest that factors beyond GFLOPs influence performance, such as model architecture and training data. The clustering of models around certain GFLOP ranges suggests potential sweet spots for performance-cost trade-offs.