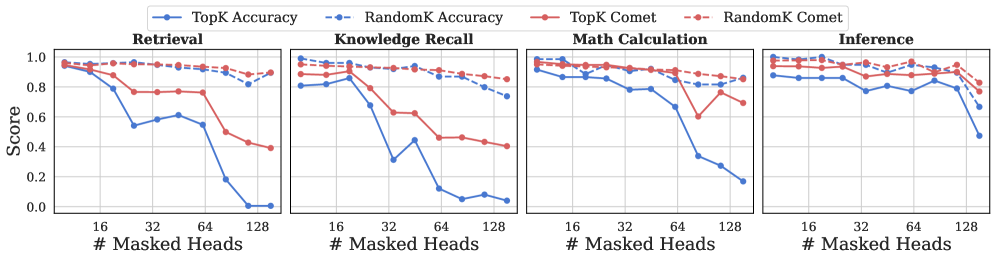
## Line Charts: Performance Comparison with Masked Heads
### Overview
The image contains four line charts comparing the performance of "TopK" and "RandomK" methods across different tasks: Retrieval, Knowledge Recall, Math Calculation, and Inference. The x-axis represents the number of masked heads (16, 32, 64, 128), and the y-axis represents the score (from 0.0 to 1.0). Each chart displays two solid lines ("TopK Accuracy" and "TopK Comet") and two dashed lines ("RandomK Accuracy" and "RandomK Comet").
### Components/Axes
* **X-axis:** "# Masked Heads" with values 16, 32, 64, and 128.
* **Y-axis:** "Score" ranging from 0.0 to 1.0 in increments of 0.2.
* **Chart Titles:** Retrieval, Knowledge Recall, Math Calculation, Inference.
* **Legend (Top):**
* Blue solid line: "TopK Accuracy"
* Blue dashed line: "RandomK Accuracy"
* Red solid line: "TopK Comet"
* Red dashed line: "RandomK Comet"
### Detailed Analysis
#### Retrieval Chart
* **TopK Accuracy (Blue Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.55 at 32 masked heads, remains relatively stable around 0.60 until 64 masked heads, then drops sharply to approximately 0.0 at 128 masked heads.
* **RandomK Accuracy (Blue Dashed):** Starts at approximately 0.95 and remains relatively stable between 0.95 and 0.80 across all values of masked heads.
* **TopK Comet (Red Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.75 at 32 masked heads, remains relatively stable around 0.75 until 64 masked heads, then decreases to approximately 0.40 at 128 masked heads.
* **RandomK Comet (Red Dashed):** Starts at approximately 0.95 and remains relatively stable between 0.95 and 0.80 across all values of masked heads.
#### Knowledge Recall Chart
* **TopK Accuracy (Blue Solid):** Starts at approximately 0.90 at 16 masked heads, decreases to approximately 0.10 at 128 masked heads, with a slight increase at 64 masked heads.
* **RandomK Accuracy (Blue Dashed):** Starts at approximately 0.95 and decreases to approximately 0.80 at 128 masked heads.
* **TopK Comet (Red Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.20 at 128 masked heads.
* **RandomK Comet (Red Dashed):** Starts at approximately 0.95 and decreases to approximately 0.85 at 128 masked heads.
#### Math Calculation Chart
* **TopK Accuracy (Blue Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.20 at 128 masked heads.
* **RandomK Accuracy (Blue Dashed):** Starts at approximately 0.95 and decreases to approximately 0.90 at 128 masked heads.
* **TopK Comet (Red Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.60 at 128 masked heads.
* **RandomK Comet (Red Dashed):** Starts at approximately 0.95 and decreases to approximately 0.90 at 128 masked heads.
#### Inference Chart
* **TopK Accuracy (Blue Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.65 at 128 masked heads.
* **RandomK Accuracy (Blue Dashed):** Starts at approximately 0.95 and decreases to approximately 0.80 at 128 masked heads.
* **TopK Comet (Red Solid):** Starts at approximately 0.95 at 16 masked heads, decreases to approximately 0.75 at 128 masked heads.
* **RandomK Comet (Red Dashed):** Starts at approximately 0.95 and decreases to approximately 0.85 at 128 masked heads.
### Key Observations
* In all four tasks, the "RandomK Accuracy" and "RandomK Comet" lines (dashed) show more stable performance as the number of masked heads increases, compared to the "TopK Accuracy" and "TopK Comet" lines (solid).
* The "TopK Accuracy" line experiences the most significant drop in performance, especially in the Retrieval and Knowledge Recall tasks.
* The "TopK Comet" line also shows a decrease in performance, but not as drastic as the "TopK Accuracy" line.
### Interpretation
The charts suggest that the "RandomK" methods are more robust to the masking of heads compared to the "TopK" methods. As the number of masked heads increases, the performance of "TopK" methods decreases significantly, indicating that these methods are more sensitive to the loss of information from specific heads. The "RandomK" methods, on the other hand, maintain a more stable performance, suggesting that they are better at utilizing the remaining information when heads are masked. This could be because "RandomK" methods distribute the attention more evenly across the heads, while "TopK" methods rely more heavily on a specific subset of heads. The Retrieval and Knowledge Recall tasks seem to be more affected by the masking of heads than the Math Calculation and Inference tasks, suggesting that these tasks may rely more on specific attention patterns.