## Bar Charts: LLM Performance Comparison
### Overview
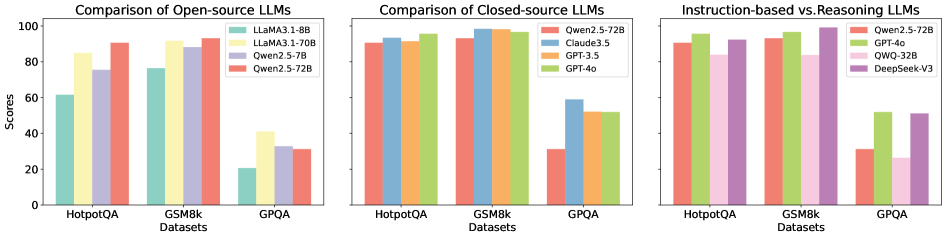
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) on three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, and the x-axis represents the datasets.
### Components/Axes
**General Chart Elements:**
* **Title (Left Chart):** Comparison of Open-source LLMs
* **Title (Middle Chart):** Comparison of Closed-source LLMs
* **Title (Right Chart):** Instruction-based vs. Reasoning LLMs
* **Y-axis Label:** Scores
* **Y-axis Scale:** 0 to 100, with tick marks at 20, 40, 60, 80, and 100.
* **X-axis Label:** Datasets
* **X-axis Categories:** HotpotQA, GSM8k, GPQA
**Legends:**
* **Left Chart (Open-source LLMs):** Located in the top-right corner of the chart.
* Light Green: LLaMA3.1-8B
* Yellow: LLaMA3.1-70B
* Lavender: Qwen2.5-7B
* Salmon: Qwen2.5-72B
* **Middle Chart (Closed-source LLMs):** Located in the top-right corner of the chart.
* Salmon: Qwen2.5-72B
* Light Blue: Claude3.5
* Orange: GPT-3.5
* Green: GPT-4o
* **Right Chart (Instruction-based vs. Reasoning LLMs):** Located in the top-right corner of the chart.
* Salmon: Qwen2.5-72B
* Green: GPT-4o
* Pink: QWQ-32B
* Purple: DeepSeek-V3
### Detailed Analysis
**1. Comparison of Open-source LLMs:**
* **LLaMA3.1-8B (Light Green):**
* HotpotQA: ~62
* GSM8k: ~77
* GPQA: ~20
* **LLaMA3.1-70B (Yellow):**
* HotpotQA: ~85
* GSM8k: ~92
* GPQA: ~25
* **Qwen2.5-7B (Lavender):**
* HotpotQA: ~75
* GSM8k: ~88
* GPQA: ~28
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~92
* GSM8k: ~94
* GPQA: ~30
**2. Comparison of Closed-source LLMs:**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~92
* GSM8k: ~95
* GPQA: ~30
* **Claude3.5 (Light Blue):**
* HotpotQA: ~93
* GSM8k: ~97
* GPQA: ~58
* **GPT-3.5 (Orange):**
* HotpotQA: ~95
* GSM8k: ~98
* GPQA: ~52
* **GPT-4o (Green):**
* HotpotQA: ~97
* GSM8k: ~98
* GPQA: ~52
**3. Instruction-based vs. Reasoning LLMs:**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~92
* GSM8k: ~95
* GPQA: ~30
* **GPT-4o (Green):**
* HotpotQA: ~97
* GSM8k: ~98
* GPQA: ~52
* **QWQ-32B (Pink):**
* HotpotQA: ~90
* GSM8k: ~92
* GPQA: ~28
* **DeepSeek-V3 (Purple):**
* HotpotQA: ~92
* GSM8k: ~94
* GPQA: ~32
### Key Observations
* **Dataset Difficulty:** All models generally perform best on GSM8k and HotpotQA, and significantly worse on GPQA.
* **Open-source Performance:** The 72B parameter version of Qwen2.5 consistently outperforms the other open-source models across all datasets. LLaMA3.1-8B performs the worst.
* **Closed-source Performance:** GPT-4o and GPT-3.5 show very high performance on HotpotQA and GSM8k, with GPT-4o slightly edging out GPT-3.5. Claude3.5 also performs well.
* **Instruction vs. Reasoning:** GPT-4o generally outperforms Qwen2.5-72B, QWQ-32B, and DeepSeek-V3, especially on GPQA.
### Interpretation
The data suggests that model size (parameter count) is a significant factor in performance for open-source models, as evidenced by the difference between LLaMA3.1-8B and LLaMA3.1-70B. Closed-source models generally outperform open-source models, particularly on the GPQA dataset, which may indicate better reasoning capabilities. The performance differences between instruction-based and reasoning LLMs on GPQA suggest that some models are better suited for complex reasoning tasks. The consistently low scores on GPQA across all model types indicate that this dataset is particularly challenging.