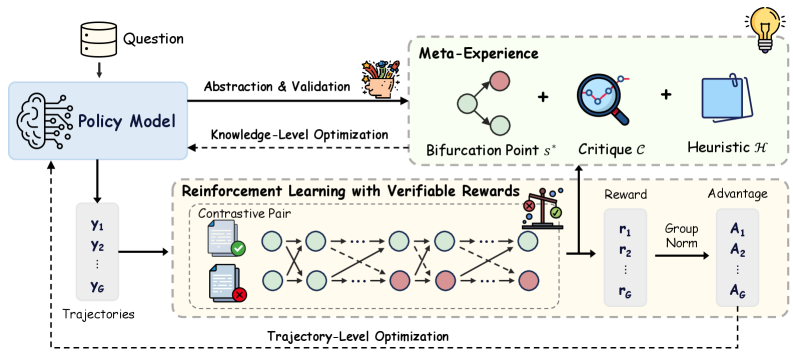
## System Architecture Diagram: Meta-Experience Enhanced Reinforcement Learning Framework
### Overview
This image is a technical system architecture diagram illustrating a reinforcement learning (RL) framework that incorporates a "Meta-Experience" module for knowledge-level optimization. The system processes a question, generates trajectories via a policy model, and optimizes using both verifiable rewards and abstracted meta-knowledge. The diagram uses icons, labeled boxes, and directional arrows to depict data flow and component relationships.
### Components/Axes
The diagram is organized into three primary, interconnected modules:
1. **Policy Model (Left Section):**
* **Input:** "Question" (represented by a database icon).
* **Core Component:** A box labeled "Policy Model" with a brain/circuit icon.
* **Outputs:** A set of "Trajectories" labeled `Y₁`, `Y₂`, ..., `Y_G`.
* **Feedback Loops:** Receives two optimization signals: "Knowledge-Level Optimization" (dashed arrow from Meta-Experience) and "Trajectory-Level Optimization" (dashed arrow from the RL module).
2. **Meta-Experience (Top-Right Section):**
* **Input:** "Abstraction & Validation" (solid arrow from Policy Model, accompanied by a basket icon).
* **Core Components:** A dashed box containing three elements summed together:
* "Bifurcation Point `s*`" (represented by a node-link diagram with green and red nodes).
* "Critique `C`" (represented by a magnifying glass over a network).
* "Heuristic `H`" (represented by a notepad/clipboard icon).
* **Output:** "Knowledge-Level Optimization" (dashed arrow pointing back to the Policy Model).
3. **Reinforcement Learning with Verifiable Rewards (Bottom Section):**
* **Input:** The "Trajectories" (`Y₁` to `Y_G`) from the Policy Model.
* **Core Process:** A dashed box detailing the RL process:
* **"Contrastive Pair":** Shows two parallel sequences of states (circles). The top sequence has a green checkmark document icon, and the bottom has a red 'X' document icon, indicating a comparison between successful and unsuccessful trajectories.
* The state sequences are connected by arrows, showing transitions and interactions (crossing arrows between the two sequences).
* A "scales" icon at the end signifies evaluation or reward calculation.
* **Outputs:**
* **"Reward":** A vector `r₁`, `r₂`, ..., `r_G`.
* **"Advantage":** A vector `A₁`, `A₂`, ..., `A_G`, derived from the rewards via a "Group Norm" (Group Normalization) step.
* **Feedback Loop:** "Trajectory-Level Optimization" (dashed arrow pointing back to the Policy Model).
### Detailed Analysis
* **Data Flow:** The primary flow is: Question → Policy Model → Trajectories → RL Module → Rewards/Advantages. A secondary, higher-level flow is: Policy Model → Abstraction & Validation → Meta-Experience → Knowledge-Level Optimization → Policy Model.
* **Mathematical Notation:** The diagram uses specific symbols:
* `Y₁...Y_G`: Represents G generated trajectories.
* `s*`: Denotes a critical "Bifurcation Point" in the meta-experience.
* `C`: Represents a "Critique" component.
* `H`: Represents a "Heuristic" component.
* `r₁...r_G`: The reward signal for each of the G trajectories.
* `A₁...A_G`: The calculated advantage for each trajectory, used for policy gradient updates.
* **Spatial Layout:**
* The **Policy Model** is the central hub on the left.
* The **Meta-Experience** module is positioned in the upper right, visually separate but connected via abstraction.
* The **RL with Verifiable Rewards** module occupies the lower half, directly processing the policy's output.
* Dashed lines represent optimization/feedback pathways, while solid lines represent the primary data flow.
### Key Observations
1. **Dual Optimization Loops:** The system explicitly separates optimization into two levels: "Trajectory-Level" (from direct RL rewards) and "Knowledge-Level" (from abstracted meta-experience).
2. **Contrastive Learning:** The RL module uses a "Contrastive Pair" mechanism, suggesting it learns by comparing successful and failed trajectory pairs rather than from isolated rewards.
3. **Meta-Experience Composition:** The meta-experience is not a single entity but a composite of structural knowledge (`s*`), evaluative feedback (`C`), and procedural rules (`H`).
4. **Group Normalization:** The use of "Group Norm" to compute advantages from raw rewards indicates a normalization step to stabilize learning across the batch of G trajectories.
### Interpretation
This diagram depicts a sophisticated RL training architecture designed for complex reasoning tasks (implied by the "Question" input). The core innovation is the **Meta-Experience** module, which acts as a form of "learning to learn." Instead of the policy model only improving from trial-and-error rewards (trajectory-level), it also receives distilled, abstract knowledge about critical decision points (`s*`), evaluative critiques (`C`), and useful heuristics (`H`). This knowledge-level optimization likely helps the model generalize better and avoid repeating fundamental mistakes.
The **Contrastive Pair** setup in the RL module suggests the system is trained in environments where the difference between a good and bad action sequence is subtle, requiring direct comparison. The overall flow suggests an iterative process where the policy generates experiences, some are abstracted into durable meta-knowledge, and both the concrete rewards and abstract knowledge are used to refine the policy. This architecture would be particularly valuable in domains like scientific reasoning, strategic planning, or complex problem-solving where understanding underlying principles (meta-experience) is as important as achieving high rewards.