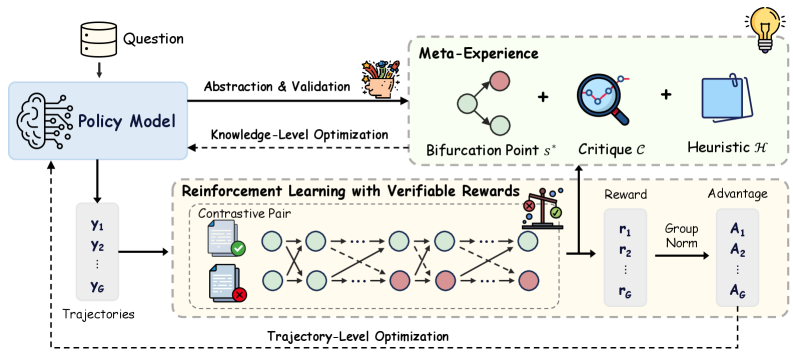
## Flowchart: AI System Architecture for Knowledge Optimization
### Overview
The diagram illustrates a multi-stage AI system architecture for processing questions and optimizing knowledge trajectories. It combines policy modeling, meta-experience, and reinforcement learning with verifiable rewards. Key components include abstraction/validation, bifurcation points, critique mechanisms, and trajectory-level optimization.
### Components/Axes
1. **Input/Output Flow**:
- **Question** (top-left): Input source
- **Trajectories** (bottom-left): Output sequences (Y₁ to Y₆)
- Arrows indicate directional flow between components
2. **Key Components**:
- **Policy Model** (blue box): Central processing unit
- **Meta-Experience** (green box): Contains:
- Bifurcation Point s*
- Critique C (magnifying glass icon)
- Heuristic H (notebook icon)
- **Reinforcement Learning with Verifiable Rewards** (yellow box): Contains:
- Contrastive Pair (green/red checkmarks)
- Reward (R₁-R₆)
- Advantage (A₁-A₆)
- Group Norm (scale icon)
### Process Stages
- **Abstraction & Validation** (lightbulb icon)
- **Knowledge-Level Optimization** (arrow from Policy Model)
- **Trajectory-Level Optimization** (bottom section)
### Detailed Analysis
- **Policy Model** receives questions and produces trajectories through two optimization stages:
1. **Knowledge-Level Optimization**: Direct connection to Meta-Experience
2. **Trajectory-Level Optimization**: Final output through Reinforcement Learning
- **Meta-Experience** integrates three elements:
- Bifurcation Point s* (decision node)
- Critique C (evaluation mechanism)
- Heuristic H (knowledge repository)
- **Reinforcement Learning System**:
- Uses **Contrastive Pair** (correct/incorrect trajectories)
- Calculates **Reward** (R₁-R₆) and **Advantage** (A₁-A₆)
- Implements **Group Norm** (normalization mechanism)
### Key Observations
1. Hierarchical structure with three main processing layers
2. Circular feedback loops between components
3. Color-coded components (blue/green/yellow) for visual distinction
4. Symbolic representations (icons) for abstract concepts
5. Quantitative elements (R₁-R₆, A₁-A₆) suggest measurable optimization metrics
### Interpretation
This architecture demonstrates a closed-loop system where:
1. Questions are processed through multiple optimization stages
2. Meta-experience provides contextual knowledge for decision-making
3. Reinforcement learning with verifiable rewards ensures trajectory quality
4. The system balances exploration (bifurcation points) and exploitation (critique mechanisms)
The use of group normalization suggests multi-agent coordination or population-based optimization. The contrastive pair mechanism indicates active learning capabilities, while the bifurcation points suggest adaptive decision-making under uncertainty. This design appears optimized for complex knowledge domains requiring both structured learning and creative problem-solving.