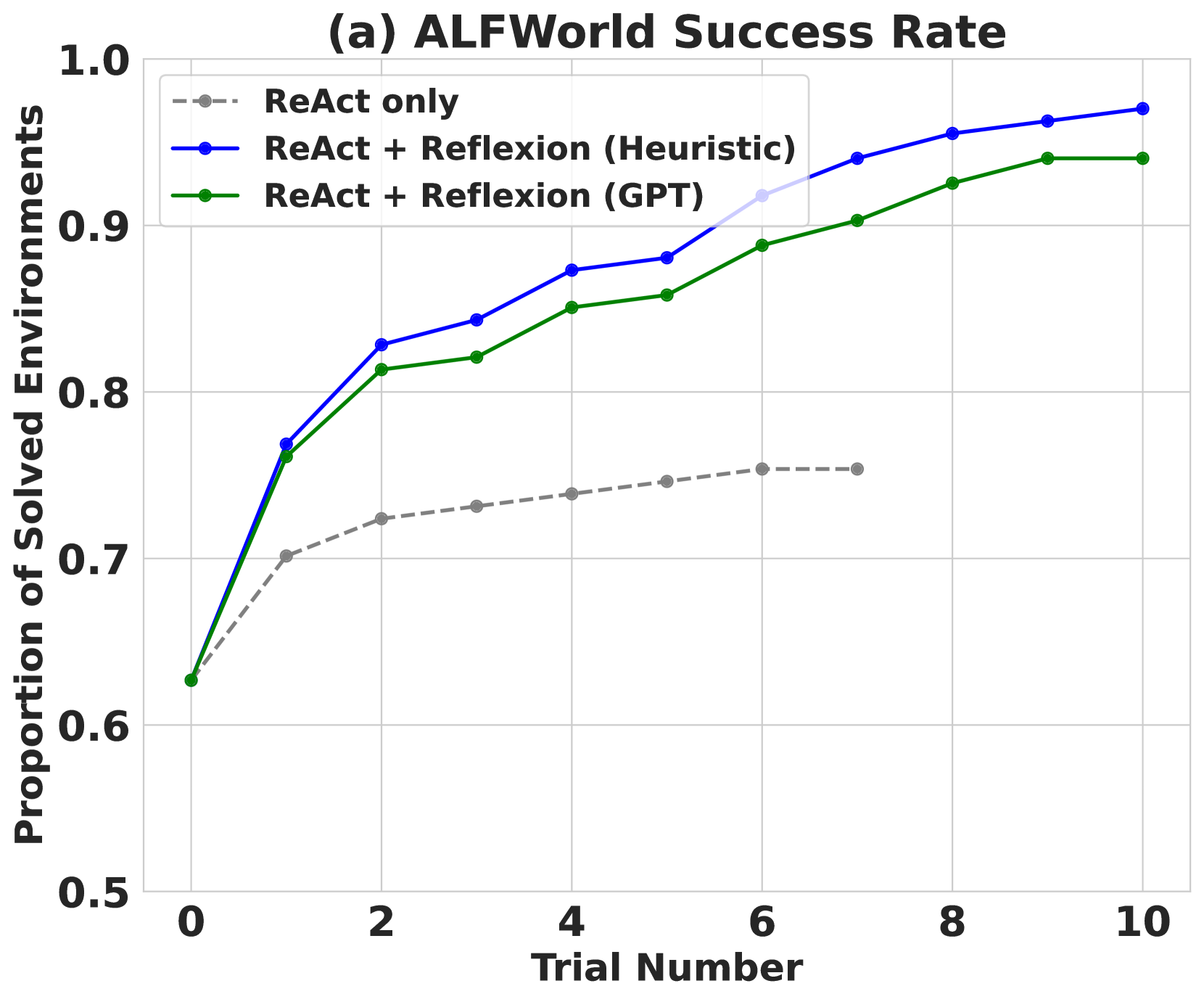
## Line Chart: ALFWorld Success Rate
### Overview
This line chart depicts the success rate of solving environments in ALFWorld across different trial numbers, comparing three approaches: ReAct only, ReAct + Reflexion (Heuristic), and ReAct + Reflexion (GPT). The y-axis represents the proportion of solved environments, ranging from 0.5 to 1.0, while the x-axis represents the trial number, ranging from 0 to 10.
### Components/Axes
* **Title:** (a) ALFWorld Success Rate (top-center)
* **X-axis Label:** Trial Number (bottom-center)
* **Y-axis Label:** Proportion of Solved Environments (left-center)
* **Legend:** Located in the top-left corner.
* ReAct only (gray dashed line)
* ReAct + Reflexion (Heuristic) (blue solid line)
* ReAct + Reflexion (GPT) (green solid line)
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
The chart displays three distinct lines representing the success rates of each approach over increasing trial numbers.
* **ReAct only (gray dashed line):** This line starts at approximately 0.65 at Trial Number 0. It shows a slow, gradual increase, reaching approximately 0.77 at Trial Number 10. The line is relatively flat, indicating limited improvement with more trials.
* **ReAct + Reflexion (Heuristic) (blue solid line):** This line begins at approximately 0.81 at Trial Number 0. It exhibits a rapid increase initially, reaching approximately 0.87 at Trial Number 2. The rate of increase slows down, and the line plateaus around 0.93-0.95 between Trial Numbers 6 and 10.
* **ReAct + Reflexion (GPT) (green solid line):** This line starts at approximately 0.63 at Trial Number 0. It shows a significant increase, reaching approximately 0.85 at Trial Number 2. The line continues to increase, but at a decreasing rate, reaching approximately 0.96 at Trial Number 10.
Here's a more detailed breakdown of approximate values at specific trial numbers:
| Trial Number | ReAct only | ReAct + Reflexion (Heuristic) | ReAct + Reflexion (GPT) |
|--------------|------------|-------------------------------|--------------------------|
| 0 | 0.65 | 0.81 | 0.63 |
| 2 | 0.74 | 0.87 | 0.85 |
| 4 | 0.76 | 0.90 | 0.91 |
| 6 | 0.77 | 0.93 | 0.94 |
| 8 | 0.77 | 0.94 | 0.95 |
| 10 | 0.77 | 0.95 | 0.96 |
### Key Observations
* The ReAct + Reflexion approaches (both Heuristic and GPT) consistently outperform the ReAct only approach across all trial numbers.
* The ReAct + Reflexion (GPT) approach achieves the highest success rate, particularly at higher trial numbers.
* All three approaches show diminishing returns in success rate as the trial number increases, suggesting a point of saturation.
* The initial gains are most significant, indicating that the early trials are crucial for learning and improvement.
### Interpretation
The data suggests that incorporating Reflexion, whether using Heuristic or GPT-based methods, significantly improves the success rate of solving environments in ALFWorld compared to using ReAct alone. The GPT-based Reflexion demonstrates the highest performance, indicating that leveraging the capabilities of a large language model for reflection enhances the problem-solving process. The diminishing returns observed at higher trial numbers suggest that the agents are approaching their maximum performance level within the given environment and task. This could be due to the complexity of the environment or the limitations of the algorithms themselves. The initial rapid improvement highlights the importance of early learning and adaptation in these types of reinforcement learning scenarios. The chart provides strong evidence for the benefits of incorporating reflection mechanisms into agent architectures for improved performance in complex environments.