\n
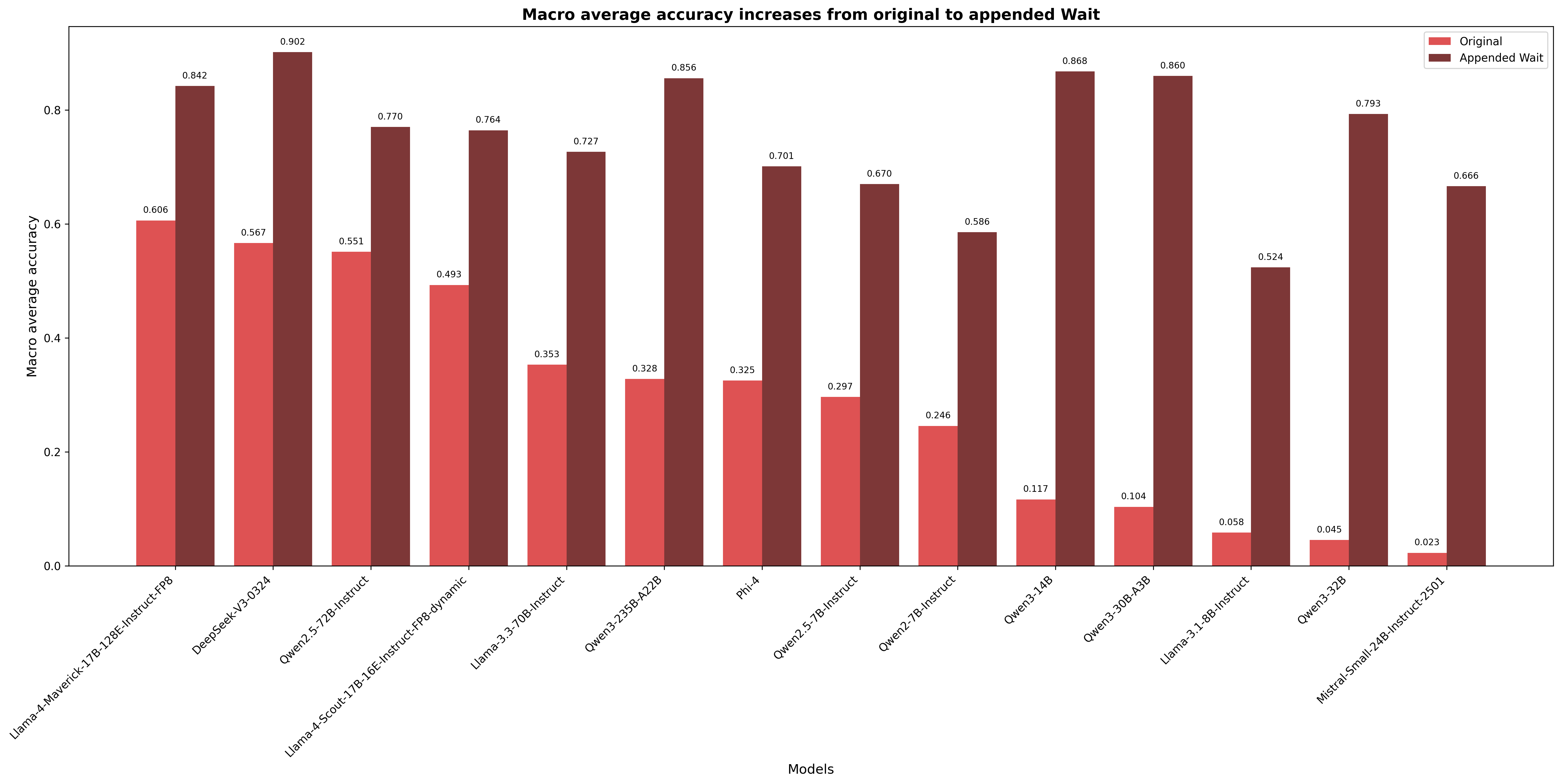
## Bar Chart: Macro Average Accuracy Increases from Original to Appended Wait
### Overview
This bar chart compares the macro average accuracy of several models, showing the difference between the "Original" and "Appended Wait" configurations. The x-axis represents different models, and the y-axis represents the macro average accuracy. Each model has two bars: one for the original configuration and one for the appended wait configuration.
### Components/Axes
* **Title:** "Macro average accuracy increases from original to appended Wait" (centered at the top)
* **X-axis Label:** "Models" (centered at the bottom)
* **Y-axis Label:** "Macro average accuracy" (left side, vertical)
* **Y-axis Scale:** Ranges from approximately 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner.
* "Original" - represented by the color red (#E41A1C)
* "Appended Wait" - represented by the color grey (#377EB8)
### Detailed Analysis
The chart displays accuracy values for 14 different models. The following data points are extracted, noting the color corresponds to the legend:
1. **Llama-2-7b-hf-GPTQ:**
* Original (Red): Approximately 0.606
* Appended Wait (Grey): Approximately 0.842
2. **Deepseek-v2-0324:**
* Original (Red): Approximately 0.567
* Appended Wait (Grey): Approximately 0.902
3. **Openchat-3.5-7B:**
* Original (Red): Approximately 0.551
* Appended Wait (Grey): Approximately 0.770
4. **Llama-2-7b-hf-16E instruct-prg-dynamic:**
* Original (Red): Approximately 0.493
* Appended Wait (Grey): Approximately 0.764
5. **Llama-3-3.70B-instruct:**
* Original (Red): Approximately 0.353
* Appended Wait (Grey): Approximately 0.727
6. **Open-2-250B-427B:**
* Original (Red): Approximately 0.328
* Appended Wait (Grey): Approximately 0.696
7. **Phi-2:**
* Original (Red): Approximately 0.325
* Appended Wait (Grey): Approximately 0.701
8. **Open-2-7B-instruct:**
* Original (Red): Approximately 0.297
* Appended Wait (Grey): Approximately 0.610
9. **Open-2-7B-instruct:**
* Original (Red): Approximately 0.246
* Appended Wait (Grey): Approximately 0.586
10. **Qwen-3-14B:**
* Original (Red): Approximately 0.117
* Appended Wait (Grey): Approximately 0.868
11. **Qwen-3-30B-A30:**
* Original (Red): Approximately 0.104
* Appended Wait (Grey): Approximately 0.860
12. **Llama-3-1.8B-instruct:**
* Original (Red): Approximately 0.058
* Appended Wait (Grey): Approximately 0.524
13. **Qwen-3-52B:**
* Original (Red): Approximately 0.045
* Appended Wait (Grey): Approximately 0.793
14. **Mistral-Small-24B-instruct-2501:**
* Original (Red): Approximately 0.023
* Appended Wait (Grey): Approximately 0.666
For almost all models, the "Appended Wait" configuration demonstrates significantly higher macro average accuracy than the "Original" configuration.
### Key Observations
* The "Appended Wait" configuration consistently outperforms the "Original" configuration across all models.
* The largest improvements are observed for Llama-2-7b-hf-GPTQ and Deepseek-v2-0324.
* Even models with low "Original" accuracy, like Mistral-Small-24B-instruct-2501, show substantial gains with the "Appended Wait" configuration.
* The accuracy values for the "Original" configurations are generally lower than those for the "Appended Wait" configurations.
### Interpretation
The data strongly suggests that the "Appended Wait" technique significantly improves the macro average accuracy of these models. This could be due to several factors, such as allowing the model more time to process information, reducing the risk of premature responses, or improving the model's ability to handle complex queries. The consistent improvement across all models indicates that the "Appended Wait" technique is a robust and effective method for enhancing model performance. The large gains observed in some models (e.g., Llama-2-7b-hf-GPTQ) suggest that certain models may benefit more from this technique than others. The fact that even models with initially low accuracy show substantial improvements highlights the potential of this technique to rescue underperforming models. The chart provides compelling evidence for the effectiveness of the "Appended Wait" strategy and suggests it should be considered for deployment with these models.