\n
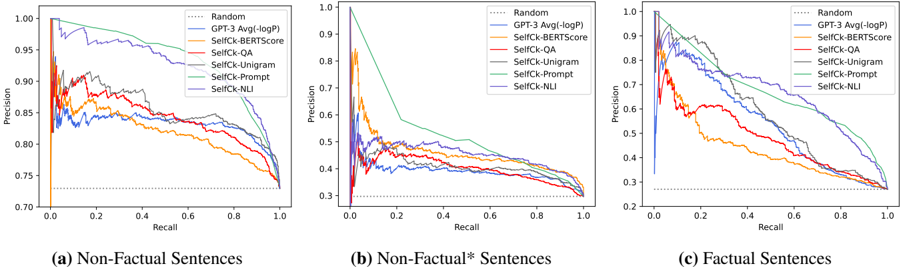
## Chart: Precision-Recall Curves for Different Models
### Overview
The image presents three precision-recall curves, each corresponding to a different type of sentence: (a) Non-Factual Sentences, (b) Non-Factual* Sentences, and (c) Factual Sentences. Each curve represents the performance of several models – Random, GPT-3 Avg(logP), SelfCk-BERTscore, SelfCk-QA, SelfCk-Unigram, SelfCk-Prompt, and SelfCk-NLI – as recall varies from 0 to 1. The y-axis represents precision, ranging from approximately 0.7 to 1.0.
### Components/Axes
* **X-axis:** Recall (ranging from 0.0 to 1.0)
* **Y-axis:** Precision (ranging from 0.7 to 1.0)
* **Legend:**
* Random (dotted black line)
* GPT-3 Avg(logP) (solid blue line)
* SelfCk-BERTscore (solid green line)
* SelfCk-QA (solid light blue line)
* SelfCk-Unigram (solid orange line)
* SelfCk-Prompt (solid red line)
* SelfCk-NLI (solid purple line)
* **Sub-Titles:** (a) Non-Factual Sentences, (b) Non-Factual* Sentences, (c) Factual Sentences. These are positioned below each chart.
### Detailed Analysis or Content Details
**Chart (a): Non-Factual Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines steadily to approximately 0.72 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 0.99 precision at 0 recall, and declines to approximately 0.82 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.98 precision at 0 recall, and declines to approximately 0.80 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.97 precision at 0 recall, and declines to approximately 0.78 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.76 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.74 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.75 precision at 1 recall.
**Chart (b): Non-Factual* Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines sharply to approximately 0.35 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.40 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.90 precision at 0 recall, and declines to approximately 0.45 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.85 precision at 0 recall, and declines to approximately 0.40 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.80 precision at 0 recall, and declines to approximately 0.35 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.75 precision at 0 recall, and declines to approximately 0.30 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.70 precision at 0 recall, and declines to approximately 0.25 precision at 1 recall.
**Chart (c): Factual Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines steadily to approximately 0.32 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 1.0 precision at 0 recall, and declines to approximately 0.35 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.99 precision at 0 recall, and declines to approximately 0.33 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.98 precision at 0 recall, and declines to approximately 0.30 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.97 precision at 0 recall, and declines to approximately 0.28 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.26 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.24 precision at 1 recall.
### Key Observations
* The "Random" model consistently performs worse than all other models across all sentence types.
* For Non-Factual and Non-Factual* sentences, the performance of all models degrades significantly as recall increases.
* GPT-3 Avg(logP) and SelfCk-BERTscore generally outperform other models in terms of precision, especially at low recall values.
* The performance gap between models is most pronounced in the Non-Factual* sentence category.
* The precision values are generally higher for Non-Factual sentences compared to Non-Factual* and Factual sentences.
### Interpretation
These precision-recall curves demonstrate the effectiveness of different models in identifying non-factual content. The significant drop in precision as recall increases for Non-Factual* sentences suggests that it is particularly challenging to accurately identify these types of sentences. The superior performance of GPT-3 Avg(logP) and SelfCk-BERTscore indicates that these models are better at capturing the nuances of language and identifying subtle inconsistencies that may indicate non-factual information. The consistently poor performance of the "Random" model serves as a baseline, highlighting the importance of using more sophisticated models for this task. The differences in performance across sentence types suggest that the characteristics of the sentences themselves (e.g., the degree of factualness) influence the effectiveness of the models. The curves reveal a trade-off between precision and recall; achieving high recall often comes at the cost of lower precision, and vice versa.