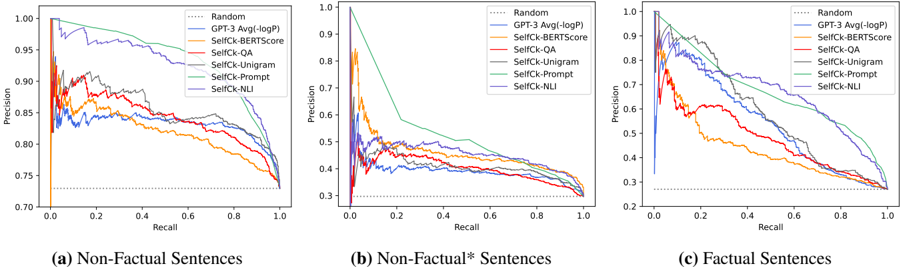
## Line Graphs: Precision-Recall Trade-offs Across Sentence Types
### Overview
The image contains three precision-recall curves comparing the performance of various natural language processing models across three sentence categories: Non-Factual, Non-Factual* (asterisked), and Factual. Each graph plots Precision (y-axis) against Recall (x-axis), with multiple data series representing different evaluation metrics or model configurations.
### Components/Axes
- **Y-axis**: Precision (0.7 to 1.0)
- **X-axis**: Recall (0.0 to 1.0)
- **Legends**: Located in the top-right corner of each graph, containing:
- Dotted line: Random (baseline)
- Solid lines:
- Blue: GPT-3 Avg(-logP)
- Orange: SelfCk-BERTScore
- Red: SelfCk-QA
- Gray: SelfCk-Unigram
- Green: SelfCk-Prompt
- Purple: SelfCk-NLI
- **Graph Labels**:
- (a) Non-Factual Sentences
- (b) Non-Factual* Sentences
- (c) Factual Sentences
### Detailed Analysis
#### Graph (a): Non-Factual Sentences
- **Trends**: All models show a downward slope from high precision at low recall to lower precision at high recall.
- GPT-3 Avg(-logP) (blue) maintains the highest precision (~0.95 at 0.0 recall, declining to ~0.85 at 0.8 recall).
- SelfCk-NLI (purple) shows the steepest decline (~0.92 to ~0.78).
- Random baseline (dotted) remains flat at ~0.75 precision.
#### Graph (b): Non-Factual* Sentences
- **Trends**: Steeper declines compared to graph (a), with precision dropping sharply as recall increases.
- GPT-3 Avg(-logP) starts at ~0.9 but falls to ~0.55 at 0.8 recall.
- SelfCk-NLI (purple) retains slightly better performance (~0.85 to ~0.65).
- Random baseline remains at ~0.75.
#### Graph (c): Factual Sentences
- **Trends**: More gradual declines, with models maintaining higher precision across recall ranges.
- GPT-3 Avg(-logP) (blue) starts at ~0.95 and drops to ~0.75 at 0.8 recall.
- SelfCk-NLI (purple) shows the best performance (~0.9 to ~0.7).
- Random baseline remains at ~0.75.
### Key Observations
1. **Model Performance**:
- SelfCk-NLI consistently outperforms other methods in factual sentences (graph c).
- GPT-3 Avg(-logP) performs best in non-factual sentences (graph a).
2. **Trade-offs**:
- All models exhibit a precision-recall trade-off, with precision decreasing as recall increases.
- The Random baseline (dotted line) serves as a reference point, showing that most models outperform random chance.
3. **Asterisked Category**:
- Non-Factual* sentences (graph b) show the most significant performance degradation across models, suggesting this subset is more challenging.
### Interpretation
The data demonstrates that model performance varies significantly depending on sentence type. SelfCk-NLI appears particularly effective for factual sentences, maintaining higher precision even at high recall levels. The steep declines in non-factual and non-factual* categories suggest these sentence types are more difficult to classify accurately. The consistent presence of the Random baseline indicates that all tested models provide meaningful improvements over chance performance. The asterisk notation in Non-Factual* may imply a specialized subset (e.g., ambiguous or context-dependent sentences), warranting further investigation into why this category poses greater challenges.