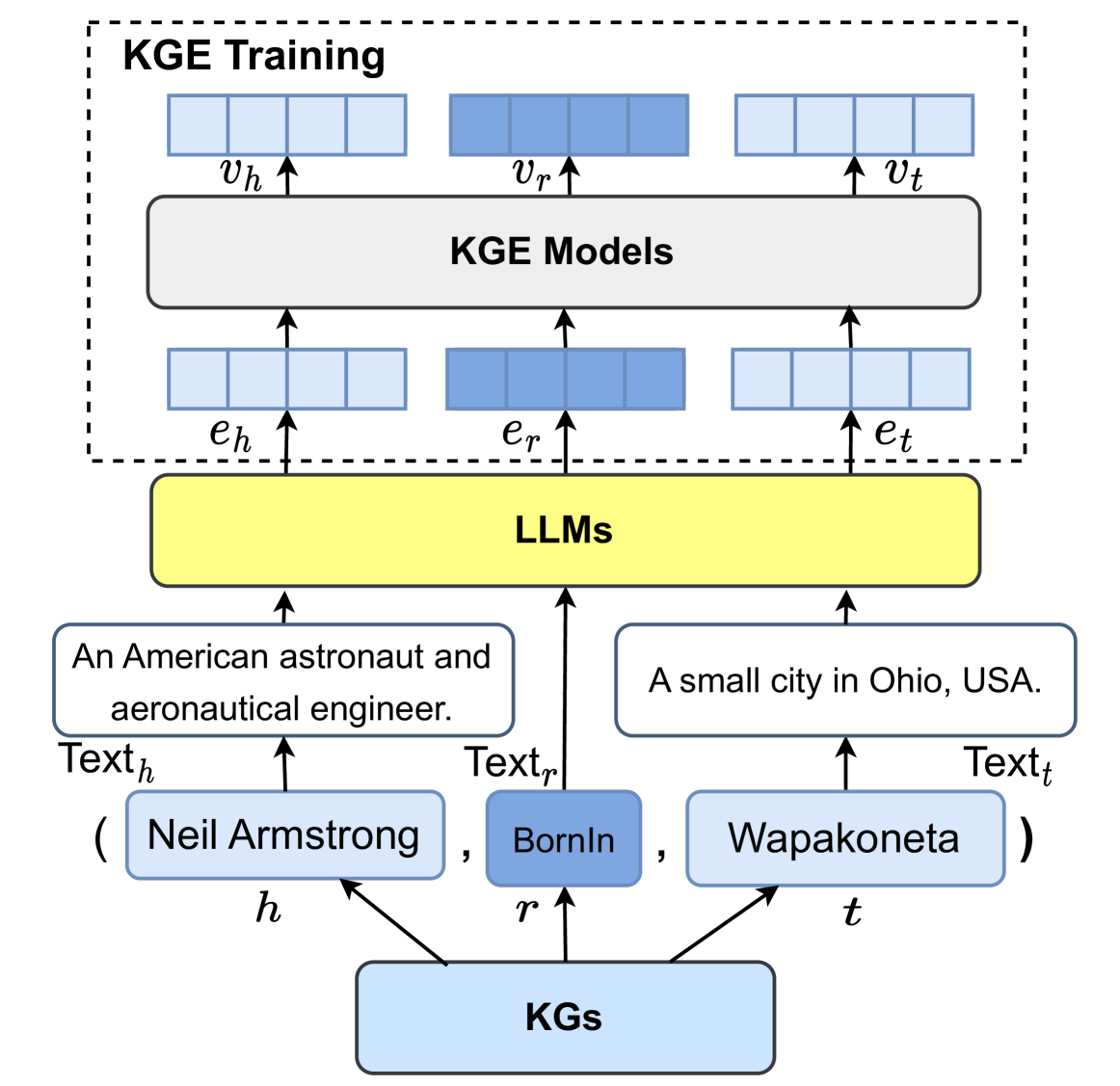
## Diagram: KGE Training Process
### Overview
The image is a diagram illustrating the Knowledge Graph Embedding (KGE) training process using Large Language Models (LLMs). It shows how information from Knowledge Graphs (KGs) is used to train KGE models, with LLMs acting as an intermediary to generate text descriptions.
### Components/Axes
* **Title:** KGE Training
* **Elements:**
* KGs (Knowledge Graphs): Located at the bottom, represented by a light blue rounded rectangle.
* h, r, t: Labels indicating head, relation, and tail entities, respectively. Arrows point from KGs to these labels.
* (Neil Armstrong, BornIn, Wapakoneta): Example entities and relation in a tuple format.
* Text<sub>h</sub>, Text<sub>r</sub>, Text<sub>t</sub>: Labels indicating text descriptions for head, relation, and tail entities, respectively.
* "An American astronaut and aeronautical engineer.": Text description for the head entity.
* "A small city in Ohio, USA.": Text description for the tail entity.
* LLMs: A yellow rounded rectangle representing Large Language Models.
* e<sub>h</sub>, e<sub>r</sub>, e<sub>t</sub>: Labels indicating embeddings for head, relation, and tail entities, respectively.
* KGE Models: A dark gray rounded rectangle representing Knowledge Graph Embedding Models.
* v<sub>h</sub>, v<sub>r</sub>, v<sub>t</sub>: Labels indicating vectors for head, relation, and tail entities, respectively.
* KGE Training: A dashed rectangle enclosing the KGE Models and the vectors.
### Detailed Analysis
1. **KGs (Knowledge Graphs):**
* Located at the bottom of the diagram.
* Connected to 'h', 'r', and 't' which represent the head, relation, and tail entities.
* Example tuple: (Neil Armstrong, BornIn, Wapakoneta)
2. **Text Descriptions:**
* Text<sub>h</sub>: "An American astronaut and aeronautical engineer."
* Text<sub>r</sub>: Not explicitly provided in the image, but implied to be a textual representation of the "BornIn" relation.
* Text<sub>t</sub>: "A small city in Ohio, USA."
3. **LLMs (Large Language Models):**
* Positioned above the text descriptions.
* Connects the text descriptions to the KGE models.
4. **KGE Models:**
* Located at the top of the diagram, within the "KGE Training" box.
* Receives embeddings (e<sub>h</sub>, e<sub>r</sub>, e<sub>t</sub>) from the LLMs.
* Outputs vectors (v<sub>h</sub>, v<sub>r</sub>, v<sub>t</sub>).
5. **Flow:**
* KGs -> (h, r, t) -> (Entities and Relation)
* (Entities and Relation) -> (Text Descriptions)
* (Text Descriptions) -> LLMs
* LLMs -> (e<sub>h</sub>, e<sub>r</sub>, e<sub>t</sub>)
* (e<sub>h</sub>, e<sub>r</sub>, e<sub>t</sub>) -> KGE Models
* KGE Models -> (v<sub>h</sub>, v<sub>r</sub>, v<sub>t</sub>)
### Key Observations
* The diagram illustrates a process where knowledge from KGs is converted into text by LLMs, which is then used to train KGE models.
* The flow starts from structured data in KGs, transforms it into natural language, and then back into embeddings for KGE training.
### Interpretation
The diagram depicts a method for leveraging LLMs to enhance KGE training. By using LLMs to generate text descriptions of entities and relations, the system can potentially capture more nuanced and contextual information from the KGs. This approach could improve the quality of the embeddings learned by the KGE models, leading to better performance in downstream tasks such as knowledge graph completion or relation prediction. The use of LLMs bridges the gap between structured knowledge and natural language understanding, potentially enriching the training data for KGE models.